

AI integration is harder than it looks. Most engineering teams assume it’s just about connecting APIs or running pilots. But scaling AI systems to production is where 95% of projects fail. Why? Poor integration practices.
Here’s what teams often overlook:
- Data is messy: Over 80% of enterprise data is unstructured, making preparation time-consuming and error-prone.
- Infrastructure isn’t ready: Prototypes can’t handle production-level demands without scalable systems like microservices and AI gateways.
- Skills are lacking: Teams often lack the expertise to handle AI’s probabilistic nature, requiring new testing methods and workflows.
- Ethics and governance are neglected: Bias, hallucinations, and compliance issues can derail projects if not addressed early.
Only 11% of companies have successfully scaled generative AI. To succeed, you need a structured approach that tackles these challenges upfront. This article breaks down the pitfalls and offers actionable strategies to move AI projects from pilot to production.
Why most AI products fail: Lessons from 50+ AI deployments at OpenAI, Google & Amazon
Challenge 1: Data Preparation and Quality Problems
One of the biggest hurdles in integrating AI lies in underestimating the challenges of data preparation. Many engineering teams mistakenly treat it as a quick task before diving into the "real work." However, data preparation actually consumes over 80% of the time in AI projects, leaving only 20% for model development [8]. This disconnect between expectations and reality explains why 58% of organizations identify data quality issues as the primary reason AI projects stall [9].
Legacy systems compound the problem by storing information using deterministic logic – everything is either true or false, 0 or 1. AI models, on the other hand, operate probabilistically. They require data to be standardized, vectorized, and contextualized using structured ontologies [2]. Transforming data to meet these requirements isn’t as simple as exporting and importing files. The process is far more intricate. Let’s explore how fragmented data and the lengthy cleaning process further complicate AI integration.
Disconnected Data Sources Create Incomplete Datasets
AI data is rarely consolidated in one location. Instead, it’s scattered across CRMs, ERPs, legacy systems, and numerous other tools that don’t communicate with one another [2][8]. Take, for instance, a North American hospital that saw its AI project fail because critical data was spread across 20 legacy systems, making integration nearly impossible.
This disconnect often leads to what’s known as the "pilot trap." During pilot projects, engineers manually clean offline datasets in controlled environments, resulting in initial success. But when scaling to production, they face the challenge of integrating fragmented, real-time data from multiple sources. This fragmentation can cause "toxic rows" – corrupted or incomplete data entries – that lead to model hallucinations and inaccurate outputs. Such errors erode user trust and necessitate costly retraining cycles [2].
Data Cleaning Takes More Time Than Expected
Even after consolidating data, cleaning it to meet AI standards is a massive undertaking. The process involves removing errors, addressing missing values, standardizing formats, and eliminating biases, all while maintaining data lineage to ensure nothing is lost during transformation. This becomes especially complex when converting structured databases into the unstructured formats required by generative AI [2][6].
Gartner predicts that by 2026, 60% of AI projects will fail due to late, messy, or biased data [7]. The statistics are telling: 70% of high-performing organizations report challenges in integrating data into AI models, specifically pointing to quality and governance issues [6]. Manual verification often becomes a bottleneck because domain expertise is hard to encode into automated systems [6]. For example, a global investment firm spent two weeks building pipelines to extract tabular data from unstructured documents, adding versioning and relevancy scoring to ensure production-grade quality [6].
"If machine learning systems are going to learn from this data, then this data needs to be clean, accurate, complete, and well-labeled… garbage in is garbage out." – Cognilytica White Paper [8]
Challenge 2: Infrastructure Limits and Security Risks
Beyond data challenges, infrastructure limitations present a major hurdle when scaling AI systems. Developing a demo prototype is one thing, but creating a production-ready AI system is a completely different ballgame. Many engineering teams underestimate the gap between these stages, only to discover their infrastructure can’t handle the demands of production. As AWS engineers Ratan Kumar, Jeffrey Zeng, and Viral Shah aptly state:
"Prototypes are easy, demos are cool, but production is hard" [12].
The transition from a proof of concept to a fully operational system changes the game entirely. During the prototype phase, the focus is on feasibility, with less attention paid to performance and cost. But in production, these factors take center stage, influencing every architectural decision [4]. Teams that fail to prepare for this shift often find themselves rebuilding systems that struggle to scale, secure sensitive data, or manage operational costs effectively. Bridging the gap between prototype success and production stability requires significant resource investment.
Moving from Prototype to Production Demands More Resources
AI systems require far more computational resources in production than during prototyping. Single-machine setups that work for demos often collapse under the weight of real-time, large-scale demands. Production environments typically need specialized hardware like GPUs or TPUs [14]. For instance, new OpenAI accounts start with an approved usage limit of $100 per month, which only increases as usage expands [13].
To handle production-level demands, monolithic applications often need to be restructured into scalable microservices. These microservices manage tasks like data ingestion, retrieval, summarization, and orchestration. Teams may need to implement an AI gateway to coordinate multiple Large Language Models, securely handle API keys, and balance loads across regions to manage rate limits [4]. Additionally, robust data pipelines are essential for tasks like vector embeddings, chunking strategies for retrieval-augmented generation, and "Memory as a Service" to maintain session and long-term state across agents [4][14].
A survey of 28 businesses revealed that 89% lacked the necessary tools to secure their machine learning systems [16]. This highlights a critical infrastructure gap, especially when teams realize that features like streaming, caching layers, and automated evaluation systems aren’t optional – they’re essential for production-grade AI.
Overlooked Security Audits and Compliance
Once resource and scalability challenges are addressed, security becomes the next major concern. AI systems face unique vulnerabilities that differ from traditional software risks, yet many teams rely on outdated security practices. For example, AI models can inadvertently leak sensitive training data, accept malicious inputs that corrupt future predictions, or make decisions that are legally indefensible. Google cautions:
"using unauthorized training data can cause long-lasting risks" [10].
However, teams often neglect to document the origin and lineage of their training datasets and pretrained models, leaving them exposed to potential issues.
The AI supply chain introduces new attack vectors. Since training large models from scratch is computationally expensive, many teams use transfer learning or fine-tune pretrained models [10]. This approach assumes the base model is secure, but verifying this requires cryptographic checks of datasets and frameworks [16]. Microsoft highlights a key concern:
"Machine Learning models are largely unable to discern between malicious input and benign anomalous data" [15].
This underscores the importance of implementing Decision Integrity techniques and real-time guardrails to filter harmful or inaccurate outputs [4][17].
Managing access control in AI environments adds another layer of complexity. Role-Based Access Control (RBAC) should be applied to data lakes, feature stores, and model hyperparameters to prevent unauthorized access [17]. Forensic logging is also critical, capturing details like algorithm weights, confidence levels, and timestamps to ensure transparency in decision-making [15]. Jack Molloy, Senior Security Engineer at Boston Consulting Group, stresses:
"Designing and developing secure AI is a cornerstone of AI product development at BCG. We already implement best practices found in [Microsoft’s] framework" [16].
These infrastructure and security issues highlight the need for careful planning and resource allocation, setting the stage for tackling skills gaps and ethical concerns in upcoming discussions.
Challenge 3: Missing Skills and Knowledge Gaps
Even the best infrastructure can’t compensate for a team’s lack of expertise in hybrid AI and engineering. Traditional software engineering operates on deterministic logic – where the same input always yields the same output. In contrast, AI systems work probabilistically, meaning the same prompt can produce multiple valid results. This fundamental difference requires a shift in mindset and skillset.
"I’d rather use a spreadsheet or a desk calculator from the 70s for basic math than trust any LLM to do it." [18]
This shift pushes engineering managers to decide whether off-the-shelf AI models are enough or if custom models – requiring in-depth machine learning expertise – are necessary. Testing methods also need to evolve. Traditional unit tests, which check for exact outputs, must give way to property-based tests that evaluate whether results meet broader criteria like clarity or correct formatting [18]. Data engineering becomes even more critical, with teams needing skills in areas like data chunking, managing vector databases, and using Retrieval Augmented Generation (RAG) to connect models with internal data [2]. Since large language models can hallucinate at rates of 20% to 30% [2], human-in-the-loop workflows are essential to identify and fix errors. Bridging this expertise gap demands a blend of software engineering precision and AI’s adaptive methodologies.
Teams Need Both Engineering and AI Knowledge
Blending deterministic engineering with adaptive AI approaches is no small feat. Engineers used to predictable, cause-and-effect systems often struggle with large language models (LLMs). Even at low temperature settings, these models can produce outputs with more variability than traditional systems [18]. To manage this unpredictability, teams need a deep understanding of architecture, including how to break down complex AI tasks into smaller, modular microservices – a method often called "Compound AI Systems" [4].
Cost efficiency is another critical skill. Inefficient prompts can result in an average of 3.5 iterations per user query, adding about $0.03 per inference. However, using pre-approved, standardized prompts can improve efficiency by up to 15 times [2]. According to the Deloitte Center for Integrated Research:
"Generative artificial intelligence success asks leaders to do more than adopt technology. They need to seamlessly collaborate across data, engineering, and business teams throughout the software development life cycle." [2]
Without this collaboration, teams risk building systems that look impressive in demos but fail under real-world conditions. Alternatively, they may over-complicate solutions that could have been handled more efficiently with simpler models.
What Engineering Managers Should Do
Closing this skills gap requires proactive leadership that balances technical innovation with practical upskilling. Engineering managers should establish structured learning pathways that don’t disrupt day-to-day work. A great starting point is an experimentation phase. Teams can use sandbox environments to test self-hosted open-source models or third-party APIs with "opt-out of training" options to protect proprietary data [18]. Before deploying AI tools across the company, it’s vital to establish clear data policies that define what information can and cannot be shared with these models.
Another effective strategy is adopting a tiered model approach. Use fast, cost-effective models for straightforward tasks, reserving more powerful and expensive models for complex scenarios where higher confidence is needed [4]. Encouraging collaboration between data architects, software engineers, and business teams throughout the development process is also essential [2]. Additionally, creating a standardized library of prompts can cut down on trial-and-error efforts and reduce costs [2]. For teams lacking internal expertise, partnering with external specialists who understand both engineering and AI can speed up progress without the long ramp-up time required to build these capabilities in-house.
sbb-itb-51b9a02
Challenge 4: Ethical Issues and Governance Gaps
In the race to develop and deploy AI-driven products, speed often takes precedence. However, rushing to implement AI features without thorough ethical reviews can lead to significant risks, including bias, compliance problems, and a loss of user trust. While 63% of organizations now consider generative AI a top priority, a staggering 91% admit they feel unprepared to implement it responsibly [21]. Frequently, ethical issues only become apparent after users interact with the product, resulting in costly fixes and potential damage to a company’s reputation.
Engineering teams often focus on making models function technically, sometimes overlooking the broader risks. Even when the code operates as intended, AI systems can still produce harmful or biased outputs.
AI Models and Embedded Bias
AI models are trained to recognize patterns in data, but these patterns often mirror the biases present in the training sets. One particularly thorny issue is "color-blind" fairness – treating all demographic groups the same, even when ethical or legal standards call for differentiated treatment. In fact, models labeled as "fair" failed to meet these standards in roughly 25% of cases where distinctions were legally or ethically required [19].
For instance, religious organizations may have specific hiring criteria, or medical fitness standards might differ depending on the context. AI trained on generalized datasets often lacks the nuance to account for these variations, leading to flawed decisions.
A key contributor to this problem is the lack of transparency in data provenance. Many engineering teams rely on "compounded datasets", which are created by combining multiple sources. This process often strips away critical information about the original data – such as its source, whether consent was given, or its licensing status [20]. Without this transparency, it becomes nearly impossible to spot inherent biases or avoid legal pitfalls like copyright infringement or privacy violations. As a result, teams struggle to predict how their models will behave across different user groups.
"AI training data organization and transparency remains opaque, and this impedes our understanding of data authenticity, consent, and the harms and biases in AI models." – Shayne Longpre, Robert Mahari, et al. [20]
Adding to the ethical complexity are hallucinations – instances where AI generates factually incorrect or biased outputs. Recent studies show that large language models produce such errors in 20% to 30% of cases [2]. When these models generate statements that appear human-like or emotive, users may mistakenly trust the content, leading to over-reliance. This anthropomorphism can reduce critical scrutiny and amplify the impact of embedded biases.
Regulatory Challenges and Internal Resistance
The risks associated with AI bias are further complicated by regulatory and organizational challenges. Governments around the world are introducing stricter AI regulations. For example, the EU AI Act emphasizes transparency and risk assessments, while the U.S. Executive Order on Safe, Secure, and Trustworthy AI sets federal standards [21]. These regulations often require detailed documentation, which many teams fail to prioritize during development. Ignoring governance planning early on can result in expensive retrofits to achieve compliance later.
Internally, resistance to AI adoption can also be a barrier. Employees may question the value of AI, especially when its implementation seems to lack a clear business purpose – a scenario McKinsey refers to as the "tech for tech" trap [3]. Without a clear explanation of how AI aligns with organizational goals or adds value, stakeholders may doubt whether the risks are worth the investment. At the same time, legal and privacy teams may raise liability concerns, while business units worry about customer reactions to AI-generated content.
Security risks further complicate governance efforts. AI adoption can expose organizations to threats like AI-enabled malware, deepfake impersonations of company representatives, and intellectual property theft [21]. These risks, often external, can impact a company regardless of its internal AI practices. To address these challenges, organizations need robust security measures and a cross-functional steering group. This group – comprising legal, privacy, and compliance experts – should meet regularly to review and manage risks. Without this level of oversight, teams may struggle to identify and mitigate problems before they escalate.
Closing these ethical and governance gaps is just as critical as addressing the data and infrastructure issues discussed earlier. Without a comprehensive approach, organizations risk falling short of both user expectations and regulatory demands.
How AlterSquare‘s I.D.E.A.L. Framework Solves AI Integration Problems
AI Integration Challenges vs AlterSquare I.D.E.A.L. Framework Solutions
The obstacles we’ve discussed – data quality issues, infrastructure bottlenecks, skill gaps, and ethical concerns – are why 80% of AI projects fail to move beyond the experimental stage[22]. These challenges stall production readiness, but AlterSquare’s I.D.E.A.L. Framework offers a structured approach to turn AI integration into a practical business strategy.
Instead of leaving teams stuck in isolated experiments, the framework connects each AI initiative to measurable outcomes. It also lays the groundwork for infrastructure, governance, and skill development. Research shows that organizations with standardized AI tools and workflows are 3.5 times more likely to achieve high performance[24]. The I.D.E.A.L. Framework provides precisely that structure.
Discovery & Strategy Phase
The first step in the I.D.E.A.L. Framework is a comprehensive strategic assessment. This phase challenges the common belief that having more data automatically means readiness for AI. In reality, while 91% of organizations acknowledge the importance of a reliable data foundation for AI, only 55% believe they actually have one[22]. Instead of focusing on sheer data volume, this phase emphasizes the importance of data quality, governance, and accessibility.
The framework uses ontologies to standardize data, preparing it for probabilistic models[2]. It also sets up data lineage and provenance records right from the start, ensuring solid governance and compliance with regulatory standards[10].
"Quality, stewardship and relevance matter exponentially more than raw quantity." – Assad Mansour, Contributor, CIO[22]
Beyond data, this phase addresses non-functional requirements like privacy, scalability, and maintainability before any coding begins[23]. It identifies specific, high-impact applications and aligns stakeholders on clear success metrics. For example, instead of vague goals like "use AI in marketing", it focuses on measurable targets such as "reduce customer churn by 20%." This clarity helps avoid "pilot purgatory", where projects fail to scale beyond initial trials[24].
Agile Development and Validation Phase
Once the foundation is in place, the next phase focuses on iterative development, ensuring AI capabilities meet real-world product needs. The framework prioritizes rigorous data cleaning to fix issues like missing values, duplicates, and incorrect labels that could skew model outcomes[10]. Complex datasets are broken into manageable parts, maintaining consistency across multimodal inputs[2].
To address scalability, the framework uses Infrastructure as Code (IaC) tools like AWS CDK or Terraform, enabling secure and consistent deployments[4][11]. It also integrates AI gateways to centralize authentication, manage API keys, and balance workloads dynamically across regions. This ensures systems can handle limitations such as Requests Per Minute (RPM) and Tokens Per Minute (TPM)[4].
The architecture breaks down AI monoliths into modular microservices, such as RAG retrievers and data ingestion pipelines. This modularity allows for independent scaling and improves system resilience[4]. Since 90% of the AI development lifecycle involves tasks like data preparation, infrastructure setup, and application integration, rather than just model selection[10], this phase ensures that these critical areas are well-managed. Rapid prototyping and controlled testing environments further help validate ideas before committing to large-scale deployment[24].
Post-Launch Support and Continuous Improvement Phase
After deployment, the focus shifts to ensuring the system adapts to changing data and usage patterns. AI models naturally degrade as data evolves[1]. This phase incorporates MLOps for continuous monitoring, which detects "data drift" – a shift in patterns that can harm model performance[22]. The framework also maintains "data freshness" in production, ensuring models stay relevant over time[2].
AI gateways play a key role here, logging prompts, responses, and latencies in a standardized format for ongoing security audits and performance checks[4]. They also track per-request costs, like token usage and compute, to maintain financial efficiency as query volumes grow[23]. Additionally, centralized guardrails at the gateway level filter outputs from large language models (LLMs), ensuring compliance with organizational safety policies[4].
Continuous improvement is essential, especially since hallucination rates for large language models often range between 20% and 30%[2]. Regular retraining, debiasing, and optimization keep systems effective while addressing ethical concerns. Organizations that treat data as a product – investing in master data management and governance – are seven times more likely to scale generative AI successfully[22]. This disciplined approach ensures that the benefits of AI integration extend well beyond the initial launch.
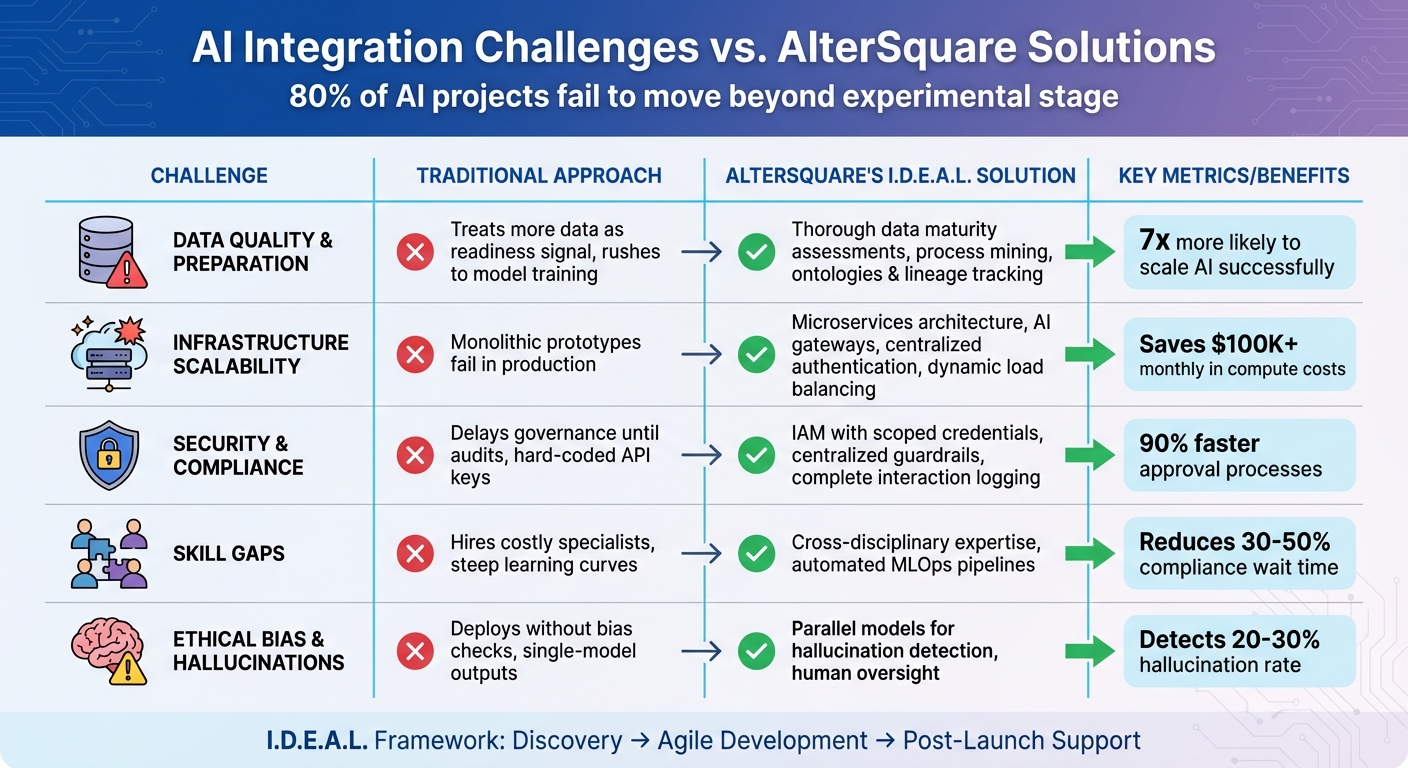
AI Integration Challenges vs. AlterSquare Solutions
Let’s break down how AlterSquare tackles common AI integration challenges with its I.D.E.A.L. Framework. These strategies directly address the gaps that contribute to the failure of 80% of AI projects [22]. Below is a table that connects major challenges to AlterSquare’s solutions, highlighting the benefits specifically for startups.
| Challenge | Traditional Approach | AlterSquare’s I.D.E.A.L. Solution | Startup Benefit |
|---|---|---|---|
| Data Quality & Preparation | Treats more data as a sign of readiness and rushes into model training. | Conducts thorough data maturity assessments during the discovery phase using process mining [22] and enforces ontologies and lineage tracking [2]. | Enables scalable data integration, making organizations 7x more likely to scale AI successfully [22]. |
| Infrastructure Scalability | Relies on monolithic prototypes that don’t work well in production environments. | Implements microservices architecture in the agile phase, featuring AI gateways for centralized authentication and dynamic load balancing [4]. | Cuts over $100,000 in monthly compute costs from inefficient prompting [2] and supports independent scaling [4]. |
| Security & Compliance | Delays governance until audits and hard-codes API keys. | Utilizes IAM with scoped, short-lived credentials [25] and centralized guardrails that log all interactions [4]. | Speeds up approval processes by as much as 90% [27] and minimizes the impact of security breaches. |
| Skill Gaps | Hires costly specialists or struggles with steep learning curves. | Offers cross-disciplinary expertise and automated MLOps pipelines [26]. | Reduces 30–50% of time spent waiting for compliance clarity [27]. |
| Ethical Bias & Hallucinations | Deploys models without bias checks and depends on single-model outputs. | Uses parallel models post-launch to detect hallucinations (baseline 20–30% [2]) with human oversight [27]. | Prevents discrimination, avoids regulatory issues, and builds trust as data patterns evolve. |
This table highlights how AlterSquare’s targeted solutions address traditional shortcomings, paving the way for smoother AI integration.
Conclusion: Preparing Teams and Systems for AI
Bringing AI into product development isn’t just about adopting new technology – it’s a shift that impacts data systems, team expertise, security measures, and ethical considerations. The four key hurdles – data preparation bottlenecks, infrastructure scaling challenges, skill shortages, and ethical vulnerabilities – explain why nearly 90% of machine learning failures are tied to poor implementation practices rather than issues with model quality [1].
Thinking of AI as a simple plug-and-play solution overlooks its complexities. Fragmented data undermines model performance, prototype systems often crumble under production demands, and teams lacking diverse expertise struggle with AI’s probabilistic behavior. On top of that, weak governance can lead to issues like bias or hallucinations, eroding user trust and inviting regulatory scrutiny [2].
To tackle these obstacles, a well-structured approach is critical. AlterSquare’s I.D.E.A.L. Framework offers a roadmap: breaking AI systems into microservices, setting up centralized AI gateways for better security and cost management, and embedding governance from the very beginning. The framework’s discovery and agile phases ensure scalable infrastructure and controlled compute costs [2]. This systematic approach directly addresses the challenges, paving the way for smoother AI integration.
The disparity between the 5% of AI projects that make it to production [28] and the 40% stuck in pilot phases [5] boils down to preparation and clear processes. Teams must break down complex tasks into smaller, manageable components, involve forward-deployed engineers who collaborate with domain experts, and use human-in-the-loop systems to catch errors early. Jaan Tallinn captured this well:
"Building advanced AI is like launching a rocket. The first challenge is to maximize acceleration, but once it starts picking up speed, you also need to focus on steering" [1].
Achieving success requires constant monitoring, retraining, and flexibility. By standardizing data ontologies, implementing MLOps pipelines, and managing token usage costs, organizations can set themselves up to scale AI effectively. This ensures they avoid common pitfalls while maintaining the adaptability and reliability needed to stay competitive in the AI landscape.
FAQs
What challenges do engineering teams often face when integrating AI into production?
Engineering teams often hit a series of roadblocks when transitioning AI projects from prototype to production. A common pitfall is opting for solutions that are unnecessarily complicated – like deploying generative AI models for tasks that could be handled with simpler approaches. This tendency to over-engineer can inflate costs and make systems harder to manage. Another misstep is skipping vital steps, such as having humans evaluate model outputs or ensuring the AI aligns with clear business objectives. Without these, teams risk creating solutions that fail to deliver meaningful results.
On top of that, organizational hurdles can slow progress. Limited AI expertise, poor data quality, and inflexible processes often force teams to spend too much time on compliance, redoing experiments, or building one-off solutions that can’t be reused. Weak MLOps practices – such as lack of monitoring, retraining pipelines, or addressing bias – further complicate the scaling of AI systems.
As AI systems grow, data and model integrity issues also become more pronounced. Without thorough data checks, proper version control, and consistent validation of model performance, trust in the system can deteriorate. To navigate these challenges, teams should aim to simplify their designs, integrate human oversight, establish robust MLOps practices, and enforce strong data governance. These steps are key to building reliable and scalable AI solutions.
What’s the best way for companies to close the AI skills gap?
To bridge the AI skills gap, companies need to focus on creating AI-ready teams by blending traditional software engineering talent with experts in machine learning, data engineering, and model operations. By embedding AI specialists directly into product teams, organizations can ensure that expertise spreads organically across departments. Regular workshops, mentorship programs pairing junior developers with seasoned AI professionals, and internal hackathons can also spark ongoing learning and skill development.
Smart hiring strategies play a crucial role, too. Prioritize roles like data scientists, machine learning engineers, and ethical AI specialists. If hiring new talent isn’t feasible, partnerships with universities, research institutions, or AI service providers can be a practical alternative. These collaborations can even include "train-the-trainer" initiatives to help upskill existing teams and build internal expertise.
Lastly, integrating MLOps practices into daily operations is essential. This approach not only equips engineers with hands-on operational AI skills but also ensures models are production-ready. Automating workflows – like pipelines, monitoring, and retraining – within CI/CD processes fosters a culture of continuous improvement. This allows teams to stay competitive and scale AI solutions effectively.
Why is preparing data so important for integrating AI successfully?
Data preparation forms the foundation of any successful AI project. If your datasets are messy, incomplete, or poorly organized, your AI models may struggle with issues like bias, low accuracy, or unreliable predictions. These kinds of problems can snowball into expensive fixes and delays down the road.
The process of preparing data includes tasks like cleaning up inconsistencies, removing anomalies, and ensuring high-quality data across both structured formats (like spreadsheets) and unstructured ones (such as text or images). Taking the time to prepare your data properly not only boosts the performance of your AI models but also helps your team implement solutions more smoothly, avoiding unnecessary costs or setbacks. In short, well-prepared data ensures your AI system hits the ground running and delivers results from the start.







Leave a Reply