

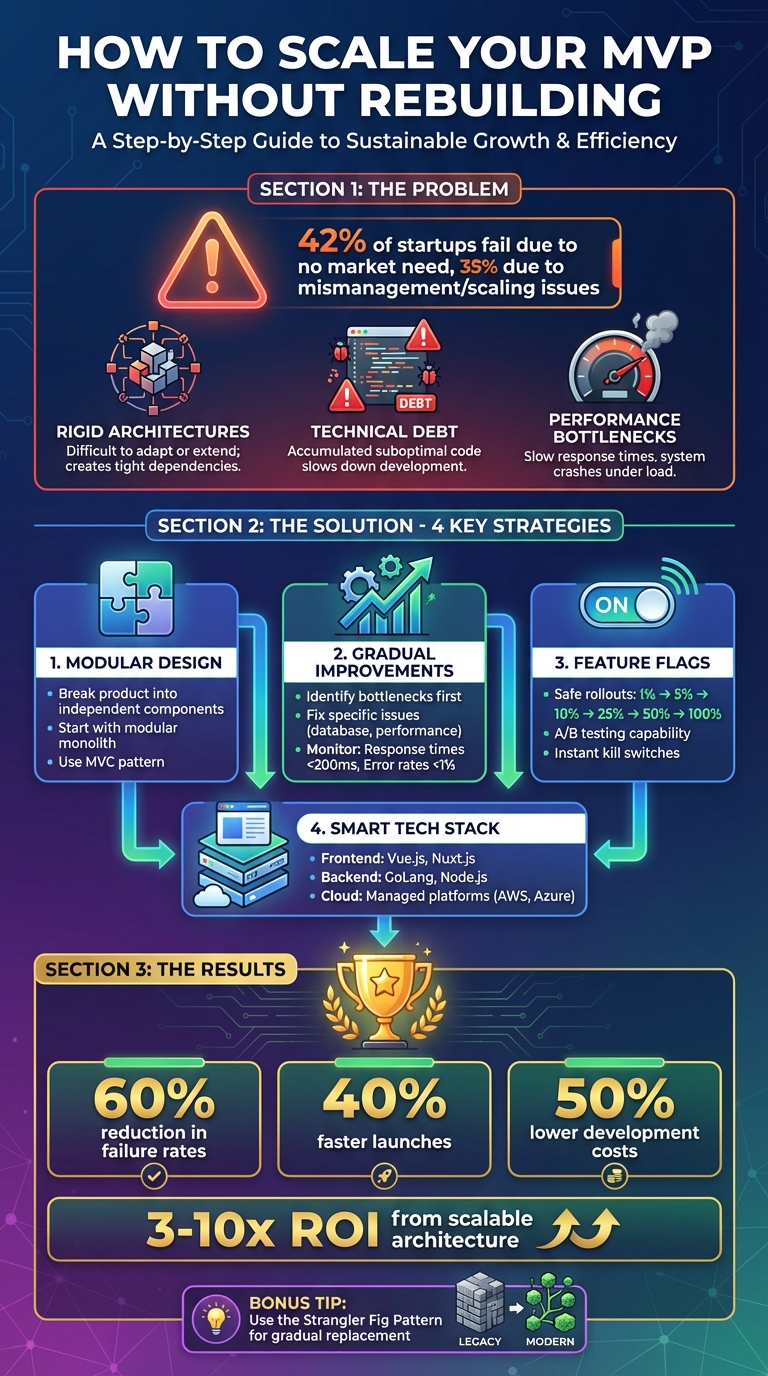
Scaling an MVP doesn’t have to mean starting over. Many startups face scaling issues because their MVPs are built with rigid architectures and technical debt. Instead of a costly rebuild, you can scale effectively by:
- Using modular design: Break your product into independent components for easier upgrades.
- Gradual improvements: Identify bottlenecks and fix specific issues like database inefficiencies or performance lags.
- Feature flags: Safely roll out updates and test changes incrementally.
- Smart tech stack choices: Opt for scalable tools like Vue.js, GoLang, and managed cloud platforms.
This approach allows you to grow your product step-by-step without disrupting users or draining resources. The key is focusing on small, targeted changes that ensure your system evolves with your business needs.
Step-by-Step Guide to Scaling MVPs Without Rebuilding
Common Problems When Scaling MVPs
As your MVP starts to gain traction, a few challenges tend to pop up. These aren’t catastrophic flaws that demand an entire rebuild, but rather growing pains from the initial design and development choices.
Rigid Architectures and Non-Modular Design
Most MVPs are built with everything lumped into one central codebase – authentication, billing, and core features all tied together without clear boundaries. This setup makes changes tricky. For example, tweaking something as simple as pricing tiers could unintentionally break unrelated parts of the product, like your sign-up process or reporting tools. This kind of centralization often creates "God objects" – overloaded components that make updates risky and time-consuming.
The red flags are easy to spot: a small feature update requires touching multiple files, slowing down development and increasing the risk of errors. Regression testing becomes a lengthy process, and a shared database – where feature flags, billing data, and user profiles coexist in the same tables – only worsens the situation. When everything is interconnected, your team ends up patching issues instead of addressing the root causes, leading to growing technical debt.
Technical Debt from Early Development
Speed is the name of the game when building an MVP, but it often comes at a cost. Business rules – like pricing limits or feature access – get hardcoded into controllers instead of being placed in dedicated systems. Data models become overloaded with nullable fields serving multiple purposes, indexes are missing, and constraints are unclear. Even worse, automated tests are often neglected, making future updates risky and error-prone.
While these shortcuts might work in the early stages, they can slow you down as you scale. Experiments become harder to run, errors creep in more frequently, and manual regression testing eats up time. Inefficient database schemas and the lack of automated testing lead to performance issues like timeouts. Weak logging and metrics make troubleshooting a nightmare, pushing teams toward drastic measures like rewriting entire systems instead of targeting specific fixes. Over time, this debt snowballs into performance challenges, which brings us to the next issue.
Performance Bottlenecks That Block Growth
As your product scales, performance bottlenecks can become a major roadblock. Misconfigured databases and inefficient queries often trigger these issues. A single database instance may struggle to handle both read and write operations, especially during peak usage. Backend APIs might suffer from N+1 queries or synchronous calls, increasing endpoint latency. Meanwhile, background job processors – often under-provisioned or single-threaded – can lead to delayed notifications and growing task backlogs.
The key to solving these problems lies in identifying whether the bottlenecks are isolated or systemic. If most of the pain points are tied to specific endpoints or database tables, targeted fixes – like adding indexes, introducing caching, or refactoring problem areas – can go a long way. A full rewrite is rarely necessary unless your current stack fundamentally limits your ability to scale, which is uncommon. More often than not, the problem isn’t the framework itself but how it’s been implemented.
Modular Architecture: Building for Scale from the Start
When designing your MVP, think modular from the outset. Instead of creating a tangled, all-in-one codebase, break your application into distinct components – like authentication, billing, user profiles, and analytics. This way, each part can evolve independently. If one area needs to be optimized or replaced, you can do so without disrupting the rest of your product.
That said, don’t overcomplicate things early on. For most startups, starting with a modular monolith is the sweet spot. This means building a single application where different modules are organized into separate folders, each with clear boundaries and interfaces. It keeps deployment simple while leaving room for future flexibility.
Designing MVPs with Independent Modules
To keep things manageable, apply separation-of-concerns principles from the beginning. A great starting point is the MVC (Model-View-Controller) pattern, which separates your user interface, business logic, and data access layers. For example, this setup allows you to update your React frontend without worrying about breaking your payment processing system. On the backend, using service objects to encapsulate specific behaviors – like subscription creation or invoice generation – makes those functions easier to test, optimize, or even extract into standalone services later.
Organizing your application by business domains – such as Users, Billing, Analytics, and Notifications – helps ensure that each module evolves independently. These domains should communicate through clear APIs or events. For instance, a "UserSignedUp" event could trigger actions in the Analytics module without requiring direct data sharing. This design allows you to scale individual modules, like pulling out Analytics into its own service when query demands increase, without having to rewrite its data integration.
There’s no need to jump into microservices right away. Split components only when it makes sense – such as when resource usage, scaling requirements, or uptime needs vary significantly. AlterSquare’s discovery phase often maps user journeys to domain modules, estimating traffic for each segment. This helps identify which parts of the system are most likely to face growth challenges, enabling smart modularization without unnecessary complexity.
This approach creates a foundation that supports gradual scaling and improvement over time.
Using the Strangler Fig Pattern for Gradual Replacement
When production issues arise, progressive migration becomes key. One effective strategy is the Strangler Fig Pattern, which lets you replace problematic parts of your system step by step. Here’s how it works: introduce a routing layer, like a reverse proxy or API gateway, in front of your application. Then, build improved versions of specific modules – say a faster search engine or a revamped payment service – as standalone components. The routing layer ensures that traffic for these features is directed to the new code, while the rest of the system continues using the old setup.
Over time, you can replace more pieces, shrinking the legacy system without significant downtime. For instance, an e-commerce MVP managing 100,000 products faced challenges adding new payment methods without breaking its checkout process. By transitioning to microservices over five months, they achieved a system where new payment options could be integrated in days, and overall development speed increased by 300% [6].
To put this into action, start with a well-defined feature that’s causing pain but isn’t deeply intertwined with the rest of the system – like a pricing engine or user profile service. Build its replacement behind a stable API, then use feature flags and gradual traffic shifting to test it with small user groups. Monitor performance metrics like latency and error rates. Once the new module handles all traffic smoothly, you can retire the old code. This step-by-step method minimizes risk and ensures your product stays live and functional throughout the transition.
Choosing Tech Stacks That Support Growth
The tech stack you choose during the MVP stage can set the tone for how easily your product scales in the future. A poor choice could lead to expensive rewrites, while a solid foundation allows for smoother growth. But here’s the thing: you don’t need to design for millions of users right out of the gate. Instead, focus on frameworks and tools that balance scalability and cost-effectiveness.
Selecting Frameworks and Tools That Scale
Certain frameworks – like Vue.js, Nuxt.js, GoLang, and Node.js – are built with scalability in mind. On the frontend, Vue.js and Nuxt.js stand out because their component-based architecture lets you add features without disrupting the core codebase. On the backend, GoLang is excellent for handling concurrent requests efficiently through its goroutines, while Node.js supports horizontal scaling thanks to its event-driven, non-blocking I/O model. Both integrate seamlessly with cloud platforms like AWS and Azure, which can automatically scale resources to match traffic demands.
Managed PaaS platforms are another game-changer. They significantly reduce the need for hands-on DevOps work. According to a 2023 Forrester report, teams using managed platforms saw over a 40% boost in productivity and faster MVP launches by cutting down on complexity [5]. These platforms take care of deployment, scaling, logging, and SSL, freeing up small teams to focus on building features instead of wrangling infrastructure.
Evaluating Performance, Cost, and Complexity Trade-offs
When choosing your stack, you’ll need to juggle three critical factors: performance, cost, and complexity. Let’s break it down:
- Performance: Keep an eye on metrics like response times (target under 200ms at the 99th percentile), throughput, and error rates below 1%. GoLang is ideal for low-latency, concurrent tasks, while Node.js excels in I/O-heavy applications but isn’t as strong for CPU-intensive work.
- Cost: It’s not just about hosting fees. Think about developer salaries, onboarding time, and scaling expenses. For example, Vue.js offers a simpler learning curve, with most developers ramping up in just 1–2 weeks, which can save money compared to more complex frameworks. Cloud platforms also offer flexible pricing; AWS EC2 t3.micro instances, for instance, start at $0.10/hour, scaling resources automatically to match demand [4]. This pay-as-you-go model is perfect for startups with unpredictable growth.
- Complexity: Simplicity is key for small teams. Frameworks like Nuxt.js keep things straightforward, reducing mental overhead and allowing for faster iterations without piling on technical debt. Start lean by using managed services, lightweight CI/CD pipelines through tools like GitHub Actions, and feature flags to test changes safely. A great example is AlterSquare, which used a combination of Vue.js/Nuxt.js for its user-friendly UIs and GoLang/Node.js backends. This approach enabled them to iterate quickly, scale horizontally, and integrate with cloud platforms – all without needing costly rebuilds. Their modular design helped clients achieve growth while keeping the development process streamlined.
sbb-itb-51b9a02
How to Scale MVPs Step by Step
Scaling your MVP is all about making steady, targeted improvements. The key is to measure where things are falling short, tackle the most pressing bottlenecks, and implement changes carefully to avoid disrupting what already works. Start by identifying exactly what’s slowing your system down.
Finding and Fixing Bottlenecks First
Before diving into code changes, take the time to identify the actual problems. This means tracking application-level metrics like response times and error rates. On the infrastructure side, keep an eye on CPU usage (anything consistently over 70–80% is a red flag), memory usage, database query delays, and queue backlogs.
Using established monitoring tools is crucial here. Real scaling issues often show up as spikes in latency or errors during high traffic periods, maxed-out infrastructure even after adding resources, or a noticeable dip in performance during U.S. peak hours (8 a.m.–10 p.m. ET), which can directly hurt conversions. Focus on core user flows like login, onboarding, checkout, and search – these are the areas that directly affect your revenue. Sometimes, the solution is straightforward: adding indexes, implementing caching, optimizing queries, or offloading resource-heavy tasks. By zeroing in on these bottlenecks, you can make meaningful improvements quickly.
Safe Feature Rollouts with Feature Flags
Feature flags (also known as toggles) are a powerful tool for scaling safely. They allow you to deploy new code to production but keep it inactive until you’re ready to test it. By wrapping new or updated logic in a conditional check tied to a flag, you can control who gets access without needing to redeploy the code. This method is a game-changer for managing risk during scaling.
For example, you can run canary rollouts, where a new caching layer or search backend is enabled for just 1–5% of users initially. This lets you monitor metrics closely before rolling it out further. You can also perform A/B tests to compare different versions of a feature or use kill switches to instantly disable a problematic feature in an emergency without undoing the entire release.
Feature flag platforms make this process much easier. A safe rollout typically follows these steps: deploy the code "dark" and test it in staging; enable it only for internal users; run a small production canary (1–5%) during off-peak hours; gradually increase exposure (10% → 25% → 50% → 100%) as metrics remain stable; and finally, remove the old code path once the new feature is proven. This approach minimizes risk, whether you’re introducing Redis caching, read replicas, or other performance enhancements.
Once your features are rolled out safely, the next step is to focus on upgrading individual parts of your system.
Upgrading Individual Components Without Full Rewrites
Scaling doesn’t mean starting from scratch. You can upgrade your system piece by piece by isolating specific components behind clear interfaces. For example, you can independently replace modules for authentication, payments, or search without disrupting the rest of the system.
This modular approach is widely used for good reason. Teams often begin with a discovery phase to map out dependencies and plan safe extraction paths. From there, they use agile iterations to update one component at a time, avoiding the risks of a full system rewrite. By upgrading individual modules within a well-structured architecture, you can maintain overall stability while making meaningful progress.
How AlterSquare Helps Startups Scale Without Rebuilding
AlterSquare has developed a framework that enables startups to grow their products without the need for a complete rebuild. By leveraging their I.D.E.A.L. framework – Insight & Discovery, Design & Domain Modeling, Engineering & Experimentation, Agile Delivery & Iteration, and Launch, Learn & Lifetime Support – they ensure your product is built to handle increasing traffic and complexity from the very beginning. This structured approach allows businesses to scale incrementally alongside their growth.
Discovery & Strategy for Scalable Architecture
Before writing a single line of code, AlterSquare takes a deep dive into understanding your business. Through workshops with founders and stakeholders, they clarify your business model, growth objectives, and key success metrics. This phase focuses on mapping critical user flows – like onboarding, checkout, and search – and pinpointing which areas of your system need to scale independently.
They also document non-functional requirements, such as performance and reliability needs, and select a tech stack that aligns with your budget and long-term scalability. By laying out a phased roadmap (MVP → V1 → V2) and clearly defining modular boundaries, AlterSquare ensures your product is prepared to grow without requiring a full rebuild down the line.
Agile Development with Continuous Iteration
AlterSquare employs agile methodologies, working in two-week sprints to deliver updates efficiently. Using tools like automated CI/CD pipelines and feature flags, they deploy new code seamlessly while minimizing disruptions. Their domain-driven design approach creates loosely coupled modules – such as authentication, payments, and analytics – that can be updated or scaled independently without impacting the entire system.
To maintain performance and reliability, they conduct regular load and performance testing to catch potential issues early. By balancing the development of new features with the reduction of technical debt, AlterSquare ensures your system remains both innovative and stable. This iterative, modular approach keeps your product ready for ongoing evolution.
Post-Launch Support for Ongoing Optimization
Once your product is live, AlterSquare continues to provide robust support. They set up monitoring dashboards to track key metrics like latency, error rates, and throughput for critical services. Proactive alerts and service level objectives (SLOs) ensure potential issues are addressed before they affect users.
In addition to this real-time monitoring, monthly scaling reviews help identify areas that might need targeted refactoring or horizontal scaling. AlterSquare also offers managed DevOps support, performance audits, and dedicated sprints to reduce technical debt. By combining capacity planning with regular cost reviews, they ensure your system can handle significant growth without the need for emergency fixes. This approach frees up resources, allowing you to focus on building features that drive revenue and enhance user experience.
Conclusion
Scaling your MVP doesn’t have to mean starting from scratch. In fact, taking a strategic approach to your MVP can reduce failure rates by 60%, accelerate launches by 40%, and cut development costs by as much as 50% – all by designing with growth in mind from the very beginning[2].
The key lies in combining a modular design with scalable tech stacks like Vue.js, Node.js, and cloud-native platforms. This foundation supports growth while allowing for incremental upgrades. By focusing on specific bottlenecks, leveraging feature flags, and gradually enhancing components, you can sidestep the need for costly, last-minute overhauls.
Here’s a sobering statistic: 42% of startups fail because there’s no market need, but 35% collapse due to mismanagement or scaling issues[3]. Investing in scalable architecture upfront can deliver 3-10x ROI, thanks to fewer expensive rewrites and smoother transitions from MVP to a fully developed product[2]. These numbers highlight the importance of building with scale in mind, a practice embraced by top engineering teams.
As AlterSquare puts it: "We build it right the first time. Every line of code is architected for scale, eliminating costly rewrites at growth milestones"[1].
FAQs
What are the benefits of using modular design to scale an MVP?
Modular design makes scaling an MVP much easier by dividing it into smaller, self-contained components. This method lets teams work on, test, and roll out individual features independently, cutting down on complexity and avoiding major disruptions during updates.
With modular design, you can tweak or add features without needing to revamp the entire system. It also speeds up development cycles and keeps the product flexible as your business expands.
What happens if technical debt in an MVP isn’t addressed?
When building an MVP, overlooking technical debt can create serious problems as your product grows. Over time, an overly complicated codebase can slow down development and drive up costs. It also makes maintenance more expensive and limits your ability to adapt quickly to changes in the market.
On top of that, leaving technical debt unaddressed raises the chances of system failures and performance hiccups, which can damage the user experience and erode customer trust. Tackling technical debt early helps ensure your product scales smoothly, operates reliably, and stays on track for long-term success.
What role do feature flags play in scaling an MVP safely?
Feature flags are an incredibly effective way to scale MVPs while keeping risks in check. They allow developers to activate or deactivate specific features without requiring a full code redeployment. This means updates can be managed with less risk, thanks to gradual rollouts, controlled testing, and the ability to quickly reverse changes if something goes wrong.
With feature flags, you can release new functionality to a limited group of users, gather valuable feedback, and make adjustments – all without affecting the overall user experience. For startups looking to grow quickly and securely, this approach is a game-changer.







Leave a Reply