

AI-powered features are becoming essential for startups, but integrating them into products comes with unique challenges. Unlike traditional software, AI relies heavily on data quality, infrastructure, and ongoing performance monitoring. Here’s what you need to know:
- Costly Infrastructure: GPUs can range from $2 to $10 per hour, and underutilized resources can waste up to 40% of budgets. Techniques like quantization, spot instances, and dynamic autoscaling can help reduce expenses.
- Data Quality Issues: Poor or biased data can lead to inaccurate predictions. Solutions include debiasing datasets, synthetic data generation, and active learning to improve model reliability.
- Performance Maintenance: AI models degrade over time due to data drift and changing real-world conditions. Strategies like shadow testing, continuous fine-tuning, and robust monitoring systems are critical for long-term success.
Startups need scalable infrastructure, reliable data pipelines, and MLOps practices to overcome these barriers. Partnering with experienced engineering teams can help speed up deployment and ensure AI features deliver consistent results.
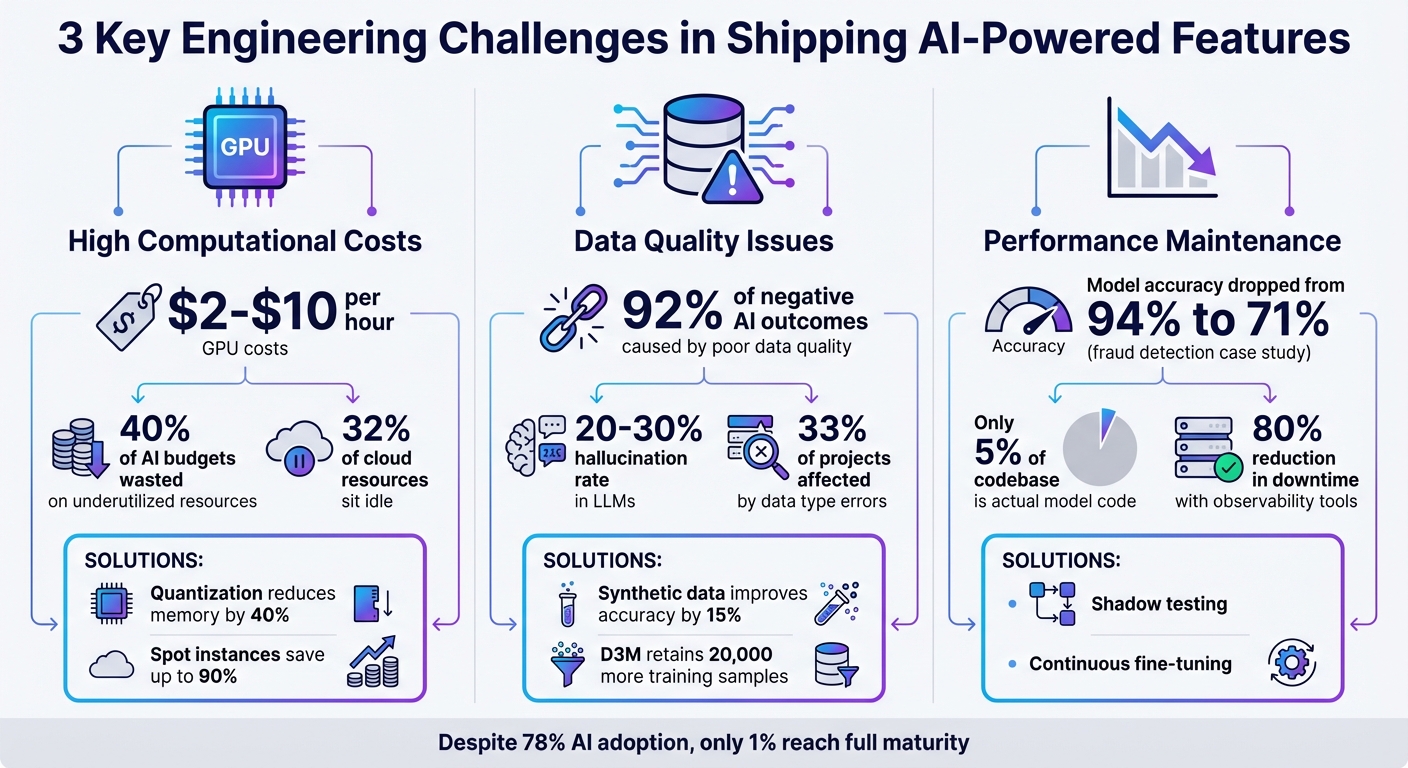
3 Key Engineering Challenges in Shipping AI Features: Costs, Data Quality, and Performance
How VEED Software Engineers Ship GenAI Features That Actually Work | Samuel Beek
Challenge 1: High Computational Costs and Infrastructure Demands
AI models demand a lot of computational power, and that doesn’t come cheap. Training and running these models require specialized hardware, primarily GPUs, which can cost anywhere from $2 to $10 per hour on major cloud platforms [7]. For startups working with limited budgets, these expenses can quickly become overwhelming.
Adding to the problem, underutilized resources can waste up to 40% of an AI compute budget, while idle or underused cloud resources account for about 32% of total cloud waste [7]. This means you’re often paying for GPUs that sit idle during off-peak times. Much of this inefficiency stems from misaligned workloads and hardware. Startups frequently over-provision resources, either out of caution or uncertainty, which accelerates budget depletion. Without careful planning, infrastructure costs can become a major roadblock to scaling AI initiatives. Finding ways to optimize these expenses is critical for keeping projects sustainable.
Managing GPU Costs Without Sacrificing Performance
One of the best ways to cut costs is to match your hardware to your workload. Not every task requires a high-end NVIDIA H100 GPU. For lighter tasks like basic inference, more affordable GPUs like the T4 or A10G can get the job done without breaking the bank. Using a top-tier GPU for tasks that don’t need that level of power is like using a race car for a quick trip to the grocery store – overkill and expensive.
Another cost-saving approach is quantization, which reduces the precision of your model. For instance, switching from FP32 to INT8 or 4-bit precision significantly reduces memory requirements. To put this into perspective, quantizing a 27B-parameter model from BF16 to INT4 shrinks memory usage from 54 GB to just 14.1 GB [7]. This can also cut memory usage and inference latency by roughly 40% [5].
Spot instances are another great option for saving money. These are unused cloud resources that can be up to 90% cheaper than standard on-demand prices [6][7]. They’re particularly useful for tasks like batch processing or training runs, especially if you use checkpointing every 10–15 minutes to safeguard your progress.
Dynamic autoscaling tools, such as KEDA or the Kubernetes Horizontal Pod Autoscaler, can help reduce costs further by scaling infrastructure down to zero during idle times. Techniques like Multi-Instance GPU (MIG) and time-slicing can also maximize GPU utilization, cutting expenses by as much as 93% [7].
While managing costs is essential, ensuring low latency is just as important – especially for real-time applications.
Reducing Latency in Real-Time AI Applications
High computational demands can also lead to latency issues, which can negatively impact user experience. In real-time applications like chatbots or recommendation engines, even small delays are noticeable and can frustrate users.
To tackle this, model optimization tools like TensorRT can reduce latency by up to 50% compared to native PyTorch. Quantization also speeds up processing, often doubling throughput while maintaining acceptable accuracy [5].
Dynamic batching is another effective strategy. By grouping multiple requests, you can maximize GPU utilization without compromising response times. For large language models, combining continuous batching with smart key-value cache management can significantly lower per-token latency [8].
Caching strategies are also a game-changer. By storing outputs for frequently used prompts or implementing semantic caches for common queries, you can eliminate redundant computations. This can reduce inference cycles by around 50% [5].
For user-facing applications, streaming responses can make a big difference. Instead of waiting for the entire output to generate, users see partial results immediately. This reduces the "Time to First Token", making the experience feel faster – even if the total generation time stays the same [8][1].
Challenge 2: Data Quality and Access Issues
Even with the most advanced infrastructure, AI models are only as good as the data they rely on. Poor-quality or biased data can lead to inaccurate predictions and unfair outcomes, which can derail AI projects. For startups, this challenge is particularly tough: they need to secure enough high-quality data while ensuring diversity to avoid bias.
Many startups still depend on outdated systems designed for binary, deterministic data. These systems struggle to handle the probabilistic and varied nature of generative AI, which often involves processing diverse data types like images, documents, and code from multiple sources [9]. This reliance on legacy systems can lead to fragmented data silos and steep preprocessing costs. Additionally, training-serving skew – when the data used for training differs from what the model encounters in real-world production – can quietly cause models to fail [11][13].
Data integrity is another pressing issue, especially in industries with strict regulations. When unstructured data is encoded into tokens for AI processing, it’s hard to ensure no information is lost. On top of that, large language models (LLMs) can generate hallucinated outputs as much as 20%–30% of the time [9]. These challenges underscore the need for strategies that address bias and ensure compliance.
Tackling Biased or Limited Datasets
Biased or imbalanced datasets are a common stumbling block. If your training data overrepresents one group and underrepresents another, your model will adopt those same biases. As Google Cloud Architecture Center explains:
"ML models learn rules from data to make a decision. Implicit bias in the data can lead models to produce unfair outcomes" [13].
Traditional methods of balancing data often involve removing certain data points, but this can reduce the overall performance of the model. A more effective solution is Data Debiasing with Datamodels (D3M), a method introduced by MIT researchers in December 2024. Using a tool called TRAK, they pinpointed specific training examples causing "worst-group error" – failures affecting minority subgroups. By removing only these problematic data points, they improved fairness while retaining 20,000 more training samples than conventional methods [15]. This research highlights that not all data points contribute equally to model performance [15].
When data is scarce or restricted by privacy laws, synthetic data can help fill the gaps. For instance, in 2022, a health insurance company developed a synthetic data platform that generated two petabytes of data for fraud prevention. This platform used probabilistic risk models to protect sensitive information [9]. Similarly, an energy company created synthetic images to train grid inspection models, improving the ability of drones to detect infrastructure defects [9]. In some cases, supplementing real data with synthetic samples can boost model accuracy by up to 15% [16].
Another effective approach is active learning, where human reviewers monitor model outputs and flag biases that automated tools might overlook [9][12]. Automated data validation pipelines can also catch issues like "schema skews" (unexpected features) or "value skews" (statistical changes) before retraining begins [11][13].
Ensuring Data Privacy and Compliance
Data quality challenges are compounded by strict privacy regulations like the CCPA in California, GDPR in Europe, and Singapore’s Model AI Governance Framework. These laws impose stringent rules on how startups can collect and use data [9][10]. Often, these regulations restrict the use of sensitive demographic data needed to identify and address bias. With only 15%–20% of customers consenting to their data being used for analytics, startups face significant hurdles in building diverse, high-quality datasets [16].
To navigate these challenges, startups must adopt measures like data anonymization and encryption to protect sensitive information from unauthorized access [10]. As CastorDoc emphasizes:
"Protecting the security and privacy of your data is paramount, especially in the age of AI. Sensitive data demands strict adherence to privacy regulations" [10].
Retrieval-Augmented Generation (RAG) offers a privacy-conscious solution. Instead of pre-training models on massive datasets, RAG enables models to fetch up-to-date information from internal databases in real time, keeping sensitive data within a controlled environment [12]. For added security, deploying an AI gateway ensures a single point of authentication, security hardening, and consistent enforcement of privacy policies across various model providers [2].
A centralized feature store can also help by ensuring that the same validated features are used for both training and production, reducing the risk of training-serving skew [11]. Additionally, tracking data lineage – monitoring the origin and transformation of datasets, code, and models – is essential for regulatory compliance and audits [14]. Regular data profiling can detect issues like "concept drift" or other quality problems before they disrupt production [13].
Challenge 3: Maintaining Model Performance in Production
Managing infrastructure and ensuring data quality are important, but keeping an AI model reliable once it’s live is where the real challenge begins. Deploying a model is just the start; the real test lies in maintaining its accuracy over time. Unlike traditional software that fails visibly, AI systems degrade quietly. As OptimusAI puts it:
"Models don’t blow up – they drift. Performance slips quietly until the impact is large and costly" [17].
Take the case of a major African bank. Their fraud detection model, trained on 2023 data, saw its accuracy plummet from 94% to 71% within a year. It failed to detect new fraud patterns emerging in 2024, and the issue only came to light during a quarterly review – after millions had already been lost [17]. This kind of silent failure highlights why startups must prioritize production monitoring when deploying AI.
Interestingly, the actual model code often makes up just 5% of the overall codebase in production. The rest? It’s infrastructure and monitoring systems [21]. Keeping AI systems running smoothly involves more than tweaking algorithms – it requires robust tools to catch problems before they affect users.
Preventing and Fixing Model Drift
Model drift happens when an AI model’s performance declines because the world it was trained to understand changes. For instance, data drift occurs when live data starts to differ from the training data. Another issue, context collapse, can impact language models when they fail to recognize new products, services, or terminology introduced after their training cutoff [17].
Even small differences between training data and live data – like changes in feature engineering – can erode a model’s effectiveness. A common issue is label leakage, where ground truth labels unintentionally influence training features. This can make a model look great offline but cause failures in real-world scenarios [19].
Uber tackled these challenges with its "Model Safety Deployment Scoring System", integrated into its Michelangelo platform. This system evaluates readiness using multiple indicators, such as offline tests, shadow deployments, and performance monitoring. Thanks to this approach, Uber onboarded over 75% of its critical models to a proactive safety framework, reducing the risk of undetected issues [20]. As Uber’s engineering team explains:
"Safety only works when it’s easy to adopt. We embed mechanisms directly into Michelangelo workflows, minimize setup, and abstract operational complexity" [20].
Shadow testing is a practical way to detect drift early. This method involves running a new model alongside the live one, processing the same inputs, and comparing outputs without impacting user-facing predictions [20]. Even a 48-hour shadow test can reveal shifts in data distribution or performance bottlenecks before they escalate [4].
Another strategy is continuous fine-tuning. Instead of retraining a model from scratch, you can update it incrementally with new information to keep it relevant [17]. Implementing data schemas and unit tests helps catch issues early, like ensuring normalized features stay within expected ranges or that rating values don’t exceed their limits [19]. Data slicing is also critical to verify that your model performs consistently across different user demographics [19]. Companies using advanced observability tools report up to an 80% reduction in AI-related downtime [18].
These safeguards not only address performance issues but also lay the groundwork for building user trust through transparency and monitoring.
Building User Trust Through Explainability and Monitoring
Beyond technical fixes, user trust in AI hinges on transparency and reliability. When an AI model makes a decision – whether it’s approving a loan or diagnosing a medical condition – users need to understand how that decision was made. Tools like OpenTelemetry can track every step of the decision-making process, offering insights into how outputs are generated [18].
For generative AI systems, a secondary model can act as a quality checker. Known as "LLM-as-Judge", this approach evaluates the relevance, helpfulness, and sentiment of the primary model’s responses. These checks can even be integrated into CI/CD pipelines, where they automatically flag builds if quality metrics like accuracy or relevance fall short [3].
Connecting technical metrics to business outcomes is another way to build trust. For example, showing how improvements in model accuracy or recall translate into higher conversion rates or better customer satisfaction can help non-technical stakeholders see the value of AI [23][24].
Human oversight remains essential for high-stakes applications. As Label Studio emphasizes:
"Evaluating an AI model isn’t just about checking accuracy, it’s about building trust" [25].
Real-time dashboards that display live metrics – like latency, token usage, or error rates – offer transparency and allow teams to respond quickly to emerging issues [18]. When ground truth labels are delayed, proxy signals like prediction drift or input data shifts can provide interim performance insights [22][24].
Finally, regular audits for bias and fairness are crucial. Monitoring for metrics like predictive parity ensures that your AI doesn’t unintentionally disadvantage certain demographic groups [24][26]. Keeping detailed documentation of model versions, training data, and incident responses also supports audits and helps meet regulatory requirements [22].
sbb-itb-51b9a02
How to Ship AI Features Efficiently
Shipping AI features efficiently requires a combination of scalable infrastructure, automated validation, and continuous monitoring. With the right tools and strategies, startups can speed up deployment without compromising quality. A major area to focus on? Rethinking infrastructure to cut compute costs.
Setting Up Scalable Infrastructure
Managing GPU costs effectively starts with smarter use of compute resources. Instead of paying for idle GPUs, consider workload-as-a-service platforms that only charge for actual usage. Pair this with GPU multi-tenancy, which allows training and inference workloads to share the same hardware, and you can significantly increase efficiency. Many organizations today only utilize 20% to 30% of their GPU capacity, but optimized orchestration can push that number to 70% or 80% [27].
Another powerful approach is heterogeneous compute orchestration, which assigns specific hardware to different tasks. For example, Nvidia GPUs are great for training, AMD chips offer better throughput per dollar for inference, and ASICs are 6 to 10 times more cost-efficient for optimized inference workloads [27]. As Brijesh Tripathi, CEO of Flex AI, explains:
"90% compute is going to be spent on inference, 10% on training" [27].
Given this shift toward inference-heavy workloads, tools like vLLM and LLM Compressor become essential. These can cut compute and storage needs by up to 50% without sacrificing performance [28]. Additionally, inference autoscaling tools can spin up new nodes in seconds, saving costs during idle periods. Implementing priority-based scheduling, which organizes workloads into categories like real-time, high-priority, and best-effort, further optimizes hardware usage and reduces expenses [27].
Creating Reliable Data Pipelines
Poor data quality is a major obstacle for AI projects, causing 92% of negative outcomes [31]. To avoid this, startups can use automated validation tools such as Great Expectations or Amazon Deequ, which run checks on new data partitions and block jobs if metrics drift [31]. These tools can catch common issues like data type errors, which affect 33% of projects, before they escalate [31].
Shifting from traditional ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform) is another game-changer. ELT takes advantage of cloud data warehouses for parallel loading and flexible reprocessing [29]. Using a Write-Audit-Publish (WAP) pattern ensures that only validated, high-quality data reaches production [30]. For privacy compliance, generative AI can create synthetic datasets that retain statistical properties while removing personally identifiable information (PII) [30].
LinkedIn offers a great example of effective data pipeline management. In June 2024, they reported that their open-source metadata search system, Datahub, was being used by over 1,500 employees to process more than 1 million datasets and support over 500 AI features. This system improved scalability by tracking metadata for every ETL step [31]. With strong data pipelines in place, the next step is to integrate MLOps for streamlined delivery.
Using MLOps for Production AI
MLOps, or machine learning operations, is typically broken into three levels: Level 0 (manual processes), Level 1 (automated pipelines for continuous training), and Level 2 (fully automated CI/CD pipelines) [33]. Advancing beyond Level 0 requires tools like a Model Registry for versioning, a Feature Store for standardized data access, and an ML Metadata Store to track lineage and reproducibility [33][34].
Platforms like MLflow, Kubeflow, and AWS SageMaker Pipelines enable seamless integration of data, models, and code [33]. MLOps also introduces Continuous Training (CT), which retrains models automatically when performance drops or when data distribution changes significantly – a solution to the model drift challenges many teams face [33]. As Google Cloud Documentation puts it:
"Only a small fraction of a real-world ML system is composed of the ML code. The required surrounding elements are vast and complex" [33].
To minimize risks during deployment, strategies like blue/green testing, canary deployments, and shadow testing are invaluable. Shadow testing, for instance, runs a new model alongside the production model, copying real-time inference requests to log responses for comparison without affecting users [32][35]. Automated checks for data schema skews (input anomalies) and data value skews (statistical shifts) before training begins ensure models remain reliable over time [33].
Expanding Your Team with Engineering-as-a-Service
For startups lacking the internal resources to implement these systems, Engineering-as-a-Service offers a practical solution. Instead of hiring full-time engineers or relying on traditional outsourcing, startups can embed experienced teams directly into their workflows.
Take AlterSquare’s Tech Team Augmentation, for example. They provide dedicated engineers with expertise in MLOps, data pipelines, and AI infrastructure. These teams handle everything from architecture design to post-launch monitoring. For startups, this means faster iterations, fewer bottlenecks, and access to specialized skills – without the overhead of building an in-house team from scratch.
How AlterSquare Helps Startups Ship AI Products
AlterSquare takes the strategies for scalable team solutions and turns them into actionable results with a clear, structured framework designed specifically for startups. Through its Engineering-as-a-Service model, AlterSquare integrates full-stack teams directly into your workflow. These teams handle everything from optimizing infrastructure and setting up data pipelines to implementing MLOps and monitoring performance after launch.
One standout feature of this approach is the 90-day MVP process, which fast-tracks development. In this program, dedicated engineers focus on tackling AI-specific constraints, such as optimizing GPU usage, ensuring smooth data flows, and maintaining consistent model performance. The process is broken into key phases: discovery and strategy, design and validation, agile development, launch preparation, and ongoing post-launch support. This ensures that every technical decision aligns with your business goals right from the start.
When it comes to AI-specific hurdles, AlterSquare’s teams bring a deep understanding of techniques like model selection hierarchies – choosing smaller, faster models (like gpt-5-nano) for simpler tasks to save costs. They also implement cost-saving optimizations, such as caching and request batching, and follow MLOps best practices. These include using model registries, feature stores, and continuous training pipelines to keep models reliable as data evolves over time [1].
The results speak for themselves. In one case, AlterSquare helped rescue a struggling project in just a few months, leading to improved revenue and profit margins. Another startup used AlterSquare’s expertise to integrate generative AI and chatbot automation, which sped up development timelines and reduced compute costs through smarter resource management. These examples highlight how AlterSquare turns complex AI challenges into opportunities for growth.
For founders who lack in-house AI expertise, AlterSquare’s Tech Team Augmentation service delivers production-ready features, allowing you to stay focused on achieving product-market fit. Whether you’re building your first AI capability or scaling an existing product, AlterSquare’s teams handle the tough technical work so you can concentrate on the bigger picture.
Conclusion
Bringing AI-powered features to life involves juggling computational costs, data quality, and long-term performance. Challenges like steep GPU expenses, data biases, and model drift explain why, even though 78% of organizations have adopted AI, only about 1% have reached full maturity with scalable infrastructure and deployment systems [4]. These hurdles highlight the need for practical, actionable solutions.
To address these challenges, strategies such as tiered deployment, automated evaluation pipelines, modular architectures, and MLOps frameworks provide a clear path forward. However, implementing these approaches requires a level of expertise that many early-stage teams lack. As Peter Norvig aptly puts it:
"Machine learning success is not just about algorithms, but about integration: infrastructure, data pipelines, and monitoring must all work together" [4].
Execution is just as critical as having the right ideas. This is where collaborating with a skilled engineering team becomes essential. AlterSquare’s Engineering-as-a-Service model is specifically designed to tackle the "production cliff" – the point where many AI projects falter. Their dedicated teams specialize in navigating the complexities of moving from prototype to production. With a 90-day MVP process, they address AI-specific challenges head-on, optimizing GPU usage, implementing cost-efficient solutions like caching and model tiering, and building robust monitoring systems to catch issues before they escalate.
Success in shipping AI features often depends on having the right technical partner. AlterSquare’s expertise helps turn complex AI problems into real-world improvements: faster development, lower compute costs, and scalable, production-ready features.
For founders working on AI-driven products, the best move is to focus on growing your business while a dedicated team handles the engineering challenges. This collaboration transforms promising prototypes into dependable, scalable solutions that deliver measurable impact.
FAQs
What strategies can startups use to reduce GPU costs when deploying AI features?
Startups can keep GPU expenses under control by fine-tuning both their software and infrastructure strategies. On the software front, self-hosting open-source models can be a game-changer. Unlike "pay-as-you-go" APIs, which charge per token, self-hosting offers more predictable and manageable costs. To further cut down on usage, techniques like model cascading, caching, and retrieval-augmented generation (RAG) can help. These approaches ensure that only the most complex queries are sent to full-scale models, while simpler tasks are handled using pre-computed or less resource-intensive solutions. Also, don’t overlook the importance of optimizing prompts and token usage – short, carefully designed prompts can significantly reduce computational demands.
On the infrastructure side, there are several cost-saving measures to consider. Batching requests can help maximize GPU utilization, while autoscaling GPU instances ensures you’re only paying for what you need as demand fluctuates. Another smart move is leveraging spot or preemptible GPU resources, which are often cheaper than standard options. To avoid any surprises, use monitoring tools to keep an eye on real-time expenses and catch potential cost spikes early. By combining these software and infrastructure strategies, startups can scale their AI capabilities without breaking the bank on GPU costs.
How can we ensure AI models stay accurate and reliable over time?
To keep AI models performing reliably, it’s important to stay on top of data drift and shifts in prediction accuracy. Set up strong logging systems and use alerts to catch problems early. Regularly compare your model’s performance against established baseline metrics to spot inconsistencies.
Integrate continuous integration and delivery (CI/CD) pipelines into your workflow. These pipelines should include automated tests and human-in-the-loop reviews to identify and address potential issues before rolling out updates. Additionally, retrain your models frequently with fresh, validated data to keep up with changing patterns and ensure they stay effective. These combined efforts help maintain the accuracy and trustworthiness of your AI models over time.
How do data privacy laws affect the development of AI features?
Data privacy laws like the California Consumer Privacy Act (CCPA) and GDPR demand that startups handle user data with strict care. For engineers, this means building systems that collect, store, and process data in line with legal standards. This often involves securing user consent, limiting the amount of data collected (data minimization), and using techniques like anonymization or pseudonymization to protect sensitive information. However, these regulations can limit the data available for training AI models, which may affect accuracy or restrict some applications.
To ensure compliance, teams need to adopt measures such as version-controlled datasets, clear retention policies, and automated processes to delete outdated records. Skipping these steps isn’t just risky – it can result in hefty fines, legal trouble, and a loss of user trust. Privacy laws also reshape how AI is developed, pushing startups to focus on privacy-first designs, conduct regular compliance checks, and implement rigorous monitoring systems before rolling out new features.






Leave a Reply