
Architectural Trade-offs When Introducing AI into Existing Systems
Huzefa Motiwala February 10, 2026
Integrating AI into existing systems is complex and requires thoughtful planning. Legacy architectures often can’t handle the unique demands of AI, such as increased latency, higher costs, and the need for scalability. Startups face three key trade-offs when adopting AI:
- Performance: AI can slow systems due to unpredictable latency.
- Scalability: AI workloads often lead to rising costs as demand grows.
- Maintainability: Frequent updates and debugging can introduce system-wide risks.
Choosing between monolithic and modular architectures is crucial. Monolithic systems are faster to launch but harder to scale, while modular architectures offer long-term flexibility but require more effort upfront. Incremental integration strategies, like refactoring or using APIs, can help bridge the gap without overhauling entire systems. For larger challenges, replatforming to cloud-native solutions provides scalability and cost efficiency.
Key steps for successful AI integration include:
- Preparing clean, organized data.
- Starting with low-risk pilot projects.
- Using tools like AI gateways and microservices for flexibility.
- Employing governance frameworks to ensure security and reliability.
AI isn’t a quick add-on; it’s a systemic shift requiring careful architectural decisions. Start small, focus on measurable outcomes, and scale strategically to avoid costly mistakes.
AI Systems Engineering: From Architecture Principles to Deployment
sbb-itb-51b9a02
Monolithic vs. Modular AI Architectures
When deciding how to integrate AI into your systems, one of the key decisions is choosing between a monolithic or modular architecture. Each option comes with its own trade-offs in terms of performance, scalability, and long-term maintenance.
Monolithic AI Systems: Quick to Launch, Harder to Scale
A monolithic AI system combines everything – data ingestion, model training, and inference – into a single codebase. For small teams of 2–5 people, this streamlined approach can simplify workflows, provide direct data access, and enable fast deployment. There’s no need for complex API gateways or orchestration layers, making it a practical choice for early-stage projects.
But this simplicity has its downsides. As the system grows, even minor updates require redeploying the entire codebase. For example, tweaking the inference logic would also mean updating the data processing and training pipelines, which can quickly become inefficient. Monolithic systems scale vertically, meaning they rely on upgrading the entire system rather than addressing specific bottlenecks. As Enrico Piovesan, Platform Architect, points out:
Monoliths weren’t built for machines. Composable systems are [7].
Modular AI Systems: More Adaptable but Requires More Work Upfront
In contrast, modular architectures break down AI functionality into separate, independent services. These components – such as data processing, model training, and inference – communicate through APIs. While this setup requires more initial planning and higher infrastructure costs, it offers significant advantages in the long run.
One of the biggest benefits is flexibility. Modular systems allow individual components to scale independently, meaning you can allocate GPUs for inference and CPUs for data processing as needed. They also make it easier to update specific parts of the system without causing downtime across the board. Research on the MASAI framework revealed a 40% improvement in AI-generated code fixes when modular designs incorporated architectural constraints [7]. Additionally, modular systems provide fault isolation; if one service goes down, the rest of the system keeps running. This resilience is critical for handling high-volume tasks like processing millions of recommendations or running frequent A/B tests.
For many teams, a common path is to start with a monolithic system for its speed and simplicity, especially when building an MVP or supporting fewer than 100,000 users. As demands grow – such as the need for frequent experimentation or handling diverse AI workloads – a modular approach becomes increasingly necessary. These architectural choices set the foundation for scalable, resilient AI systems and align with strategies for incremental integration, which will be explored next.
Strategies for Incremental AI Integration
Bringing AI into an existing system is all about taking it step by step. By using methods that limit disruption and deliver clear results, you can make the process smoother. Two standout approaches include step-by-step refactoring to prepare your system for AI and API-based hybrid integration to connect AI capabilities to your current setup.
Step-by-Step Refactoring for AI Compatibility
Start by evaluating your system using the "6 C’s" framework: cost, compliance, complexity, connectivity, competitiveness, and customer satisfaction [10]. This helps you figure out which parts of your system need immediate attention and which can wait.
The first step is preparing your data – clean it, remove duplicates, and normalize it. Once that’s done, set up automated pipelines and isolate AI logic into microservices using REST or gRPC APIs [10][1]. This way, you can scale AI components independently and keep failures from affecting the rest of your system.
AI tools can speed up this process significantly. For example, in June 2025, Amazon used its generative AI assistant, Amazon Q, to upgrade internal apps to Java 17. What used to take 50 developer days per application was cut down to just a few hours, saving $260 million annually in efficiency gains [14]. Similarly, Airbnb revamped 3,500 React component test files in only six weeks – a task that would have taken 1.5 years manually [14].
To build confidence, launch a 90-day pilot targeting low-risk, high-impact areas [10][12]. This shows stakeholders the value of AI before scaling further. Studies show that strategic AI use increases the likelihood of exceeding ROI expectations by threefold [10]. Use shadow deployments – testing with mirrored production data but no live impact – to ensure performance is solid before a full rollout [4].
This gradual approach keeps your system stable while getting it ready for AI workloads. It strikes a balance between upgrading performance and maintaining reliability. For those looking for an alternative, API-based integration offers another effective path.
Using APIs for Hybrid Integration
If refactoring feels like too much of a deep dive, API-based hybrid integration provides a simpler way to add AI features. This method focuses on creating an AI Gateway or AI Broker layer. This layer handles tasks like authentication, logging, retries, and cost controls in one place [13][3]. It prevents AI tasks from overwhelming your system and ensures smooth operations with features like rate limiting and safety filters [11].
API facades are another smart move. They modernize old system interfaces by exposing clean REST or OData endpoints, creating a secure link between legacy systems and AI features [12]. For asynchronous tasks, tools like Kafka or RabbitMQ can handle events, ensuring reliability even during high demand [12]. Implementing middleware like this typically takes just 6–12 weeks, far quicker than a full system overhaul [10].
Real-world examples show how effective this can be. In 2024, NewGlobe used APIs to link AI systems to teacher guide templates, cutting content creation time from 4 hours to just 10 minutes and saving $835,000 annually [10]. Similarly, ARC Europe introduced a GPT-powered AI agent for insurance claim assessments, reducing processing time by 83% – from 30 minutes to just 5 minutes per claim [10]. Newzip connected AI to customer data through APIs, boosting user engagement by 60% and increasing conversion rates by 10% [10].
"You do not ‘add AI’ to a SaaS product the way you add Stripe… The model is the easy part. The integration is the product." – Sebastian Heinzer, News Contributor, Technori [13]
When designing your API layer, plan for the unpredictable. AI models can hallucinate, leak data, or time out, so never let them perform privileged actions without strict safeguards [13]. Use permissions-aware retrieval to ensure RAG (Retrieval-Augmented Generation) systems check tenant and role-level access before any data is processed [13]. Companies that work with integration partners often see faster results, achieving 42% quicker time-to-value and 30% higher operational efficiency [10].
This approach is especially useful for startups with legacy systems, allowing them to add AI functionality without overhauling their entire infrastructure. By keeping clear boundaries between old and new components, hybrid integration ensures scalability while maintaining reliability.
Replatforming for AI Scalability
Sometimes, tweaking existing systems just isn’t enough. When performance hits a wall, costs spiral out of control, or technical debt makes updates a nightmare, it’s time to consider replatforming. This involves shifting AI workloads to infrastructure designed for the job – typically cloud-native platforms. These platforms offer elastic scaling, smarter resource management, and reduced overhead, making them a solid choice for handling the demands of AI.
For organizations bogged down by deployment delays and rising expenses, legacy systems can be a major roadblock [1]. Red flags include unpredictable latency during peak usage, skyrocketing API costs from inefficient resources, and fragile monolithic architectures where even minor updates can disrupt unrelated features [16].
Enterprise AI is not a ‘plug-and-play’ add-on but a systemic architecture effort. – Chandrasekar Jayabharathy, Enterprise Architect [1]
The benefits of replatforming can be game-changing. For example, in 2024, Fey, an AI-driven financial research tool, transitioned from Google Cloud Platform to a unified cloud solution. This move cut out unnecessary complexity, saving the team over $72,000 annually and allowing engineers to focus on product development instead of DevOps [19]. Similarly, Rime, an AI startup specializing in real-time voice agents, deployed its demo on a unified platform, saving an engineer about three weeks of DevOps work [19]. These examples highlight how replatforming can simplify operations and pave the way for scalable AI solutions.
Cloud-Native Platforms for AI Workloads
Cloud-native platforms tackle scalability challenges head-on, especially when compared to traditional on-premises setups. By breaking monolithic AI applications into modular microservices, these platforms allow for independent scaling [3]. Serverless architectures, for instance, can scale up during high demand and down to zero when traffic slows – something fixed hardware setups simply can’t do [17][18]. For high-demand AI workloads, Kubernetes-based platforms offer advanced GPU scheduling, including resource sharing to reduce cold-start latency for large models [5].
Cost management also gets easier. Hosting models like Llama 2 in-house can cut costs by up to 30 times per task compared to GPT-4 [16]. Cloud-native platforms also enable smarter model routing: simple queries can be directed to fast, cost-effective Small Language Models (SLMs), while complex tasks use more powerful models [16]. Features like AI gateways enhance efficiency by routing traffic across regions, bypassing rate limits, and offloading overflow traffic to elastic endpoints during spikes [3][11]. These capabilities make scaling AI workloads smoother and more efficient.
| Feature | Traditional On-Premises | Cloud-Native Platform |
|---|---|---|
| Scaling | Manual; hardware-limited | Elastic, automated, scales to zero |
| Cost | High upfront investment, fixed | Pay-per-use, with smart routing |
| Upkeep | Labor-intensive (manual updates) | Minimal (managed services) |
| Deployment | Slow, monolithic updates | Fast, modular CI/CD workflows |
Zero-Downtime Migration Strategies
Replatforming doesn’t have to disrupt your live systems. By using preview environments and phased transitions, you can move components gradually. Start by testing full-stack copies of your application, including databases and background processes, in a preview environment before pushing changes to production [19]. This approach helps catch integration issues early. Secure communication between old and new components with zero-config private networking, so you can validate everything without risking user instability [19].
Infrastructure as Code (IaC) simplifies this process, enabling reproducible environments and fast GitOps workflows [19]. Building abstraction layers into your architecture can also protect your application from vendor lock-in. For example, you could switch from OpenAI to Anthropic models without rewriting core code [19].
The goal of effective infrastructure is to become invisible, freeing your team to focus on the models, prompts, and application logic that create value. – Render Strategic Guide [19]
Plan ahead for model deprecation. Foundation models eventually age out, and systems without abstraction layers can face major disruptions during transitions [19]. Multi-layer caching can help mitigate these risks by reducing expensive model calls and lowering latency. For instance, caching at the gateway level can handle repeated queries, while caching at the knowledge layer can store frequently accessed data [3][11].
The stakes are high: 74% of engineers working with AI say consolidating toolchains is a priority to reduce fragmentation [19]. With a solid migration strategy, replatforming can turn AI scalability from a daunting challenge into a manageable reality.
Managing Technical Debt and Ensuring Maintainability
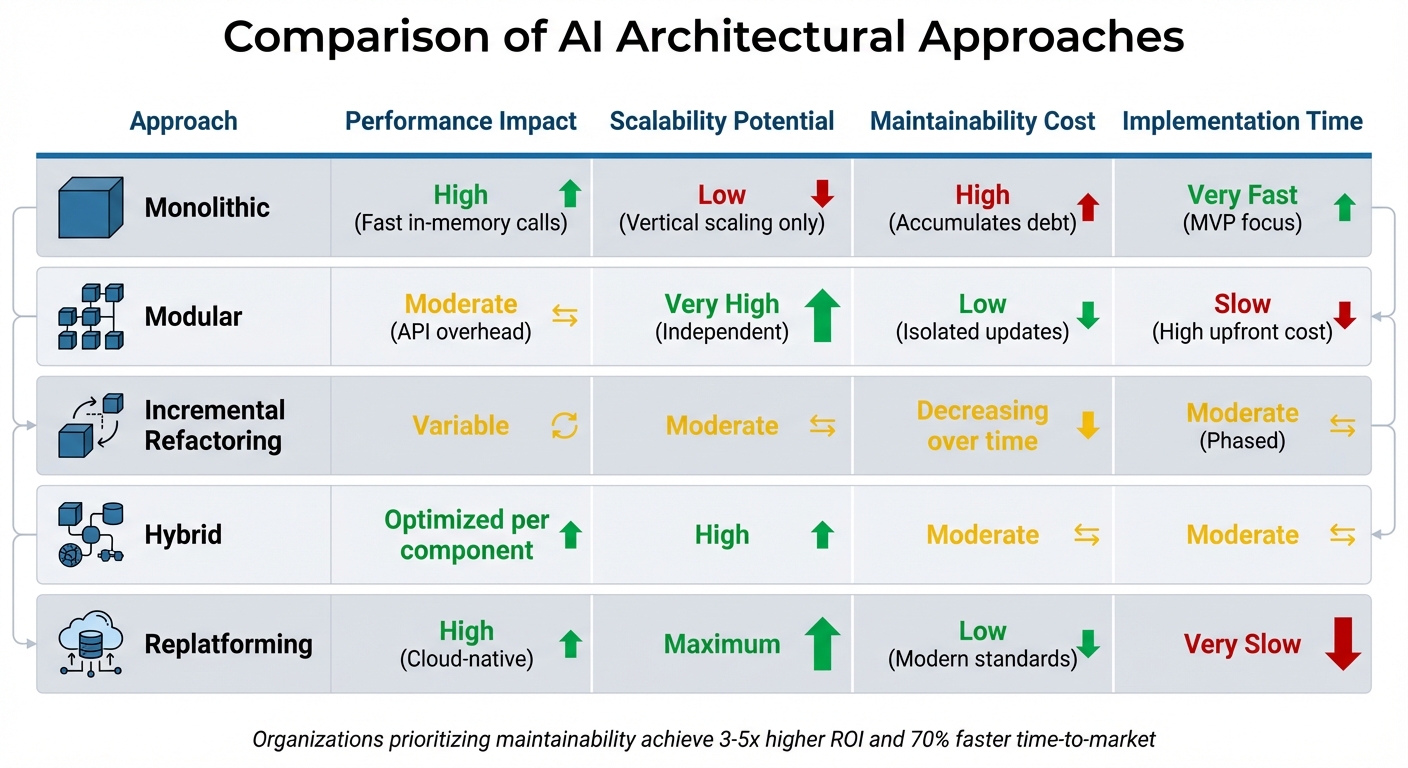
Comparison of AI Architectural Approaches for Startups
When integrating AI, managing technical debt and ensuring maintainability are essential for long-term system stability. AI systems introduce unique challenges, such as "context rot", where critical information becomes scattered across files and teams, making it difficult for any single person to fully understand the system [22]. While AI tools can analyze codebases to identify inconsistencies, the real challenge lies in determining what issues to address first.
Focus on addressing debt that impacts understandability and security. For example, "Undeclared Consumers" can create vulnerabilities, while a "Jumbled Model Architecture" complicates maintenance [21]. Advanced tools like those using knowledge-graph reasoning can map service dependencies and uncover hidden risks, such as sensitive data leaks from upstream APIs [23]. It’s worth noting that only 30% of AI implementations deliver meaningful business outcomes, often because teams treat AI as an isolated technical feature rather than integrating it into the broader system architecture [24].
"AI is now an actor, a collaborator within the business. Architects can now share the space with machines that can simulate trade-offs, generate code, detect risks, and propose solutions." – InfoQ [23]
Clear documentation is critical for reducing technical debt. "Living documentation" helps prevent infrastructure drift. AI can assist by generating "as-built" diagrams from your codebase, allowing you to compare them against intended designs and catch discrepancies early [20][23]. Netflix exemplifies this approach with its modular AI architecture. By separating data processing, model training, and A/B testing into independent services, they ensure their "Dynamic Optimization for HDR Streaming" operates within human-defined parameters [8][23]. This allows architects to focus on setting constraints rather than getting bogged down in manual configurations. Such practices also lay the foundation for effective governance, which is explored next.
Governance Frameworks for AI Systems
Governance frameworks act as guardrails, helping teams make informed decisions without unnecessary delays. For example, Azure’s Well-Architected Framework emphasizes five key areas: Reliability, Security, Cost Optimization, Operational Excellence, and Performance Efficiency [25][15]. These pillars serve as checkpoints to avoid costly errors. A practical example involves implementing quality gates that AI systems must pass before moving to production. These gates might include privacy checks for data readiness, meeting target metrics for offline quality, and defining service-level objectives for operational readiness [4].
Treat AI-related artifacts like versioned products by using centralized registries to track data assets, model checkpoints, vector indices, and prompts [4]. Prompts, in particular, should be externalized as configurations rather than hard-coded into the system. This allows non-developers to adjust them without altering the codebase [11]. Uber’s Michelangelo Platform takes this approach, enabling architects to define objectives and policies while the system autonomously handles real-time optimization, ensuring transparency and adaptability [23].
The "Three Loops" governance model provides a framework for human intervention. Strategic, high-impact decisions require an "Architect-in-the-loop", while routine, low-risk tasks can operate with an "Architect-out-of-the-loop" approach [23]. This helps avoid the "automation paradox", where increased automation leads to skill atrophy, leaving teams vulnerable when systems fail [23]. To counteract this, teams can implement "deliberate friction" by holding manual design sessions without AI tools, ensuring architects retain their ability to evaluate trade-offs independently [23].
"The architect’s primary skill remains judgment, not generation." – InfoQ [23]
Planning for model deprecation should start early. Foundation models eventually become obsolete, and systems without abstraction layers face significant disruptions during transitions [11]. Using provider-agnostic interfaces like ONNX or OpenAPI can decouple application logic from specific models, making transitions smoother [11]. Automated drift detection is also essential for identifying changes in data input distributions, performance declines, or increased policy violations [4]. Teams that consistently apply these governance practices have reported a 28% increase in design iteration speed [20].
Comparison of Architectural Approaches
Choosing the right architectural strategy depends on your organization’s current needs and constraints. Each approach has distinct trade-offs, as shown below:
| Approach | Performance Impact | Scalability Potential | Maintainability Cost | Implementation Time |
|---|---|---|---|---|
| Monolithic | High (Fast in-memory calls) | Low (Vertical scaling only) | High (Accumulates debt) | Very Fast (MVP focus) |
| Modular | Moderate (API overhead) | Very High (Independent) | Low (Isolated updates) | Slow (High upfront cost) |
| Incremental Refactoring | Variable | Moderate | Decreasing over time | Moderate (Phased) |
| Hybrid | Optimized per component | High | Moderate | Moderate |
| Replatforming | High (Cloud-native) | Maximum | Low (Modern standards) | Very Slow |
Monolithic architectures are ideal for quickly building MVPs but tend to accumulate technical debt as complexity increases. Modular systems, while requiring more upfront effort, simplify maintenance by isolating changes to individual services [8]. Incremental refactoring offers a balanced approach – beginning with a monolithic setup to validate value and later extracting components as traffic grows [8]. Hybrid architectures allow for specific optimizations while keeping other components straightforward, and replatforming provides the highest scalability but requires careful planning to avoid disruptions.
Organizations that treat maintainability as a priority from the outset often achieve 3-5x higher ROI and bring products to market 70% faster [24]. By adopting robust governance practices and carefully selecting architectural strategies, you can align your AI systems with both current needs and future growth.
Decision Framework for Startups
Choosing the right AI strategy means aligning your business goals, team capabilities, and available budget. This framework connects technical decisions with strategic objectives, ensuring AI becomes a meaningful part of your business. Rushing into AI without careful planning often leads to expensive mistakes. As Mahesh Thiagarajan, Executive Vice President at Oracle Cloud Infrastructure, explains:
The question is not whether to adopt AI, but where to apply it. Every initiative needs to tie back to a clear objective [26].
When evaluating AI, focus on three key areas: strategic importance, team expertise, and total cost of ownership.
- Strategic importance: Is AI a game-changer for your business or just solving routine problems? If it’s core to your competitive edge, custom solutions might make sense. For standard needs like authentication or payments, pre-built tools are usually more efficient [27].
- Team expertise: Hiring top-tier AI talent is expensive, which can be a challenge for early-stage startups [29].
- Total cost of ownership: Don’t just consider upfront costs. Factor in maintenance, vendor pricing, retraining, and scaling expenses [27].
Most successful startups take a hybrid approach – buying ready-made solutions for common tasks and building custom AI for areas that drive competitive advantage [27]. This lets you save time on routine tasks while focusing your resources on what matters most. A phased integration plan, like the I.D.E.A.L. Framework, can help guide this process.
The I.D.E.A.L. Framework for Phased AI Delivery
The I.D.E.A.L. Framework, developed by AlterSquare, offers a step-by-step approach to integrating AI while minimizing risks. This method focuses on incremental progress, allowing startups to test and refine their AI systems as they go. It’s similar to the "strangler fig" pattern, where new AI features are gradually introduced without disrupting existing systems [31].
Here’s how the framework works:
- Identify: Define the business problem you’re solving and set measurable success metrics, like reducing costs or improving user satisfaction [11].
- Design: Map out system pain points and decide how to break down processes into manageable parts [32].
- Execute: Start with low-risk, high-return applications to achieve quick wins and build momentum [28].
- Assess: From day one, monitor for issues like data drift or performance changes to ensure reliability [4].
- Learn: Use a disciplined release schedule (e.g., weekly updates for prompts, monthly for fine-tuning) to keep improving while maintaining stability [4].
This phased strategy has been successful across industries. For example, General Motors used AI to streamline its supply chain by treating it as a core business enabler, not just a technical experiment [30]. Similarly, BirchAI (now part of Sagility) scaled its AI solution for Fortune 500 healthcare clients with minimal engineering effort, showing how AI can shift operations from workforce-heavy to workflow-heavy [29].
Once you’ve mapped out your plan, it’s time to evaluate your readiness.
Checklist for AI Integration Readiness
Before diving into AI, assess your startup’s readiness across four areas: technical, financial, organizational, and governance. Use this checklist to pinpoint any gaps.
- Technical readiness: Is your data clean and well-organized? Do you have MLOps pipelines for version control? Consider infrastructure needs like GPU access and tools for monitoring AI performance in production [5] [4].
- Financial readiness: Have you calculated token usage and peak demand? Do you understand vendor pricing and scaling costs? Use FinOps practices to track cost-per-outcome instead of just infrastructure expenses [3] [4].
- Organizational readiness: Assign clear roles like Product Owner and Safety Lead. Train your team to understand both AI’s benefits and risks. Many AI-first startups achieve product-market fit with smaller teams due to automation [29].
- Governance readiness: Set up safeguards like PII redaction and strong encryption. Use externalized, version-controlled prompts to allow non-developers to make adjustments. Ensure you have "kill switches" for emergencies [5] [3].
| Factor | Lean Toward "Buy" | Lean Toward "Build" |
|---|---|---|
| Strategic Importance | Non-core/Commodity | Core Differentiator |
| Time to Market | Urgent/Immediate | Long-term Strategic |
| Team Expertise | Generalist/Limited | Specialized AI/Data Engineers |
| Cost Structure | Predictable OpEx | High Upfront CapEx |
| Customization | Standard/Generic | Deeply Integrated/Unique |
| Data Control | Standard Security | Proprietary/Regulated |
AlterSquare Strategies for AI Architectural Success
Tailored AI Solutions for Startups
AlterSquare approaches AI integration as a systems engineering challenge, focusing on breaking down complex applications into smaller, manageable microservices. These microservices handle tasks like data ingestion, AI gateways, and orchestration layers, ensuring that any failures are isolated and do not disrupt the entire system [3].
To boost performance and manage costs, AlterSquare employs a layered model approach. This method directs straightforward requests to faster, more affordable models while reserving advanced models for complex tasks [3]. By centralizing processes through AI gateways, they streamline authentication, manage API keys, and balance workloads dynamically across various model providers [3][11].
For long-term maintainability, AlterSquare uses workflow orchestration to manage multi-step AI processes. This ensures that if a process fails, it can resume from where it left off without redoing completed steps [2]. Observability tools are also in place to monitor data integrity, performance, and potential safety issues [4]. As MD Bazlur Rahman Likhon aptly explains:
The gap between ‘it works in Jupyter’ and ‘it survives production’ isn’t prompt engineering – it’s systems engineering [33].
To ensure smooth rollouts, AlterSquare relies on shadow and canary deployments. Shadow environments simulate production traffic without affecting live systems, while canary environments expose a small portion of live traffic to new AI features for testing before full deployment [4]. Additionally, circuit breakers and limits on reasoning iterations (typically 3–15 steps) prevent runaway costs, as demonstrated in a case where unchecked API usage led to $12,000 in expenses within 48 hours [33].
These carefully designed strategies enable startups to implement AI solutions with confidence, minimizing risks while maximizing efficiency.
Case Studies: AI Integration Success Stories
The effectiveness of AlterSquare’s approach is evident in the results achieved by companies following similar strategies. While specific client projects remain confidential, industry examples highlight the value of these methods. Take Newzip, for instance: by connecting AI to customer data through APIs, the company saw a 60% increase in user engagement and a 10% rise in conversion rates [10].
Such outcomes underscore the importance of aligning AI rollouts with business goals. Phased implementations tied to key performance indicators (KPIs) consistently deliver higher returns on investment (ROI) [10]. Partnering with experts like AlterSquare can shorten the time needed to see results by 42% and improve operational efficiency by up to 30% compared to handling integrations internally [10]. The best approach? Start small, focusing on low-risk, high-reward projects to build momentum before tackling more complex challenges.
Conclusion: Key Takeaways for AI Integration
Final Thoughts on AI Architecture Trade-offs
AI integration is a balancing act, requiring thoughtful consideration of performance, scalability, and maintainability to meet business goals. Startups that succeed treat AI as a core architectural priority. They begin with targeted, high-value use cases and expand gradually, using tools like modular microservices, AI gateways, and reliable execution frameworks.
Here’s a staggering fact: over 50% of organizations fail to deploy AI models, and even successful deployments often take more than 90 days [6]. Startups that adopt systematic approaches – such as treating AI models as products with clear ownership, well-defined roadmaps, and quality checkpoints – achieve significantly better results. For instance, teams employing structured testing protocols report 70% fewer post-deployment issues, while those focusing on high-impact legacy components see a fourfold improvement in ROI compared to teams attempting widespread automation [9].
To effectively manage AI processes, costs, and model drift, it’s essential to implement workflow orchestration, tiered model strategies, and observability tools. With 60–80% of IT budgets typically consumed by maintaining legacy systems [34], a strategic AI integration plan can help reduce this drain. By addressing these challenges, businesses can lay the groundwork for leveraging proven frameworks and methodologies.
How AlterSquare Can Help
At AlterSquare, these principles guide our approach to AI integration. We tackle these trade-offs directly, offering engineering strategies tailored to your challenges. Whether you’re building your first AI-powered feature or modernizing a legacy system, we view AI integration as a systems engineering challenge that requires precision and thoughtful planning.
Our approach involves breaking down complex applications into manageable microservices, employing layered model strategies to keep costs under control, and using workflow orchestration to ensure reliable production performance. These strategies help startups speed up development cycles, improve operational efficiency, and minimize technical debt.
For early-stage founders, our 90-day MVP program provides a fast track to launching AI features. For those wrestling with legacy systems, our architecture rescue services offer a clear path forward. AlterSquare is here to help you build AI solutions that don’t just function but thrive in real-world production environments.
Want to bring your AI vision to life? Contact AlterSquare for a consultation and take the first step toward a smarter, more efficient future.
FAQs
How do I know if my system should stay monolithic or go modular for AI?
When deciding between a monolithic and modular architecture for AI, the choice often hinges on factors like scalability, development pace, system complexity, and ease of maintenance.
Monolithic systems are often easier to start with, making them a good fit for smaller projects or simpler setups. However, as the system grows, they can become harder to adapt and maintain due to their tightly interconnected structure.
On the other hand, modular systems break down functionality into independent services that communicate through APIs. This approach allows for greater flexibility, scalability, and resilience, especially in larger or more complex systems.
To choose the right architecture for your AI integration, consider the complexity of your system, your plans for growth, and how easily you’ll need to adapt to future changes.
What’s the fastest safe way to add AI without breaking production?
The quickest and safest way to bring AI into your workflow without halting production is by using incremental refactoring and shifting to a modular, microservices-based architecture. To maintain stability, implement control measures like AI gateways, monitoring tools, and validation processes. This method strikes a balance between efficiency and reliability while keeping risks to live systems low.
When is it worth replatforming to cloud-native for AI workloads?
Replatforming to a cloud-native environment makes sense when older systems fall short of meeting the demands of AI or when modernization becomes unavoidable. Legacy architectures often bring challenges like steep costs, cumbersome processes, and struggles with performance or reliability. Transitioning to cloud-native can address these concerns, cut down on architectural debt, and provide a stronger foundation for AI-focused workloads.







Leave a Reply