
AI-Generated Code Looks Clean. Here’s Why Your Next Refactor Will Prove It Isn’t
Huzefa Motiwala March 13, 2026
AI-generated code often looks polished, but looks can be deceiving. While it adheres to formatting standards, uses clear variable names, and passes linters, it frequently hides deeper problems that emerge during refactoring. Here’s what you need to know:
- "Plausible correctness": AI code works in ideal scenarios but often fails under real-world conditions. It overlooks edge cases, introduces logic errors, and struggles with nuanced business rules.
- Hidden complexity: Issues like circular dependencies, undocumented assumptions, and bloated abstractions make future changes harder and riskier.
- Duplication and over-abstraction: AI duplicates code or forces unnecessary abstractions, leading to maintenance headaches.
- Missed edge cases: Common oversights include missing timeouts, retry logic flaws, and N+1 database queries, which can cause production failures.
- Dependency creep: AI adds redundant libraries or creates tangled dependencies without understanding the existing system.
Refactoring AI-generated code often feels like reverse-engineering someone else’s work – with no one to ask for clarification. To minimize risks, focus on early detection, structured reviews, and incremental improvements.
Key stats:
- AI-assisted pull requests have 1.7x more issues than human-written ones.
- Duplicate code rates increase from 3.1% to 14.2% in AI-heavy projects.
- 68% of AI-generated modules require complete rewrites later.
Takeaway: AI can speed up coding, but without careful oversight, it creates hidden debt that slows teams down in the long run.

The Hidden Costs of AI-Generated Code: Key Statistics on Technical Debt and Quality Issues
AI-Generated Code Is Creating a New Kind of Technical Debt
sbb-itb-51b9a02
Surface Quality vs. Actual Complexity
AI-generated code often passes surface-level checks with flying colors. It compiles without issues, adheres to naming conventions, and looks polished – almost indistinguishable from code written by a human. But this "plausible correctness" can be misleading [5]. While it may handle ideal inputs, it frequently breaks down when faced with real-world challenges like timeouts or malformed data [2][6].
The difference between how it looks and how it performs becomes glaring during refactoring. What initially seems like a clean, well-structured system often hides implicit coupling, circular dependencies, and architectural inconsistencies. These issues stem from the way AI treats each prompt as a standalone task, producing code that appears logical on its own but clashes with existing patterns and systems [1][2].
"AI-generated code is almost always correct for the world it imagines. The problem is the world it imagines doesn’t exist." – Code blows, Software Developer [6]
The statistics back this up. A review of 50 AI-generated pull requests revealed that 82% had catch blocks that failed to distinguish error types, 76% omitted critical network timeouts, and 44% introduced N+1 performance issues in database queries. These problems passed initial tests but would fail under real-world conditions [6]. AI prioritizes clean presentation over robust functionality, leaving hidden flaws that only emerge later.
Undocumented Dependencies in AI Code
AI-generated code also introduces undocumented dependencies. It connects components based solely on what’s visible in its current context, often leading to problematic relationships. For instance, Service A might rely on Service B, which then depends on Service A – a circular dependency that only becomes apparent during refactoring [4].
This issue, known as "context window isolation," means that the reasoning behind these connections exists only during the AI’s session. Once the session ends, the rationale disappears, leaving developers with a tangled web of dependencies they don’t fully understand [4][9].
"The only thing that understood the relationships in this code was the context window that produced it." – Yonatan Sason, Co-founder, Bit Cloud [4]
Over time, the impact of this problem grows. AI-assisted codebases have seen duplicate code ratios rise from 3.1% to 14.2% within a year [1]. Meanwhile, structural refactoring – essential for maintaining clean code – has dropped from 25% of all modifications to less than 10% since AI tools became widespread [10]. While AI speeds up code generation, teams end up spending far more time untangling the hidden complexities it creates.
Another issue is "dependency creep." AI often suggests new libraries without checking what’s already in use. For example, it might add date-fns to a project that already uses dayjs, leading to redundant code and bloated bundles [1]. These aren’t functional bugs, but they reflect architectural decisions made without awareness of the existing system.
When AI Overcomplicates Simple Solutions
AI doesn’t just create hidden dependencies – it also overcomplicates solutions. It often detects similar-looking code and forces unnecessary abstractions. This syntactic duplication approach fails to recognize that identical-looking code can serve entirely different purposes [3]. For example, merging a UserCard and a ProductCard into a single "UniversalCard" might seem efficient, but it results in a bloated component filled with conditional logic. When these features later require separate updates, the abstraction becomes a maintenance nightmare [3].
The data paints a clear picture. In AI-assisted projects, average file sizes increased from 142 lines to 267 lines in just one year, while cyclomatic complexity doubled from 4.2 to 8.1 [1]. AI also tends to create monolithic files – 600-line modules that combine UI, business logic, and API calls. These files might look orderly but are nearly impossible to test or modify independently [4].
"Duplication is far cheaper than the wrong abstraction." – Sandi Metz [3]
AI-generated code often introduces architectural patterns from its training data, regardless of whether they fit your project. For instance, it might implement a full Repository pattern in a project that relies on direct data access or add unnecessary service layers [1]. While these patterns aren’t inherently flawed, they create "abstraction mismatches" that fragment your system and make future changes exponentially harder.
A particularly troubling consequence is epistemic debt – the growing gap between the volume of code and the team’s understanding of it [7]. AI generates code faster than developers can fully grasp its purpose or structure. The result? A system that "works" on the surface but lacks a coherent architectural vision. When the time comes to fix or refine it, every change feels like a risky gamble rather than a calculated engineering decision [11].
"Technical debt makes code hard to change. Epistemic debt makes code dangerous to change." – Stanislav Komarovsky, Software Engineering Researcher [11]
What Goes Wrong When You Refactor AI Code
Refactoring AI-generated code often exposes deeper structural problems hidden beneath its polished surface. While the code may initially seem functional, attempts to modify, expand, or adapt it to actual use cases often reveal flaws that lead to costly rewrites or risky workarounds. These issues typically arise from missing edge cases, duplicated code, and a lack of understanding of business logic.
Missing Edge Cases That Break Production
AI-generated code often assumes an ideal world where everything works perfectly. It expects external services to respond instantly, database queries to always return expected results, and network calls to never hang [6]. These assumptions might hold up during development, but they crumble under real-world conditions, causing significant issues in production.
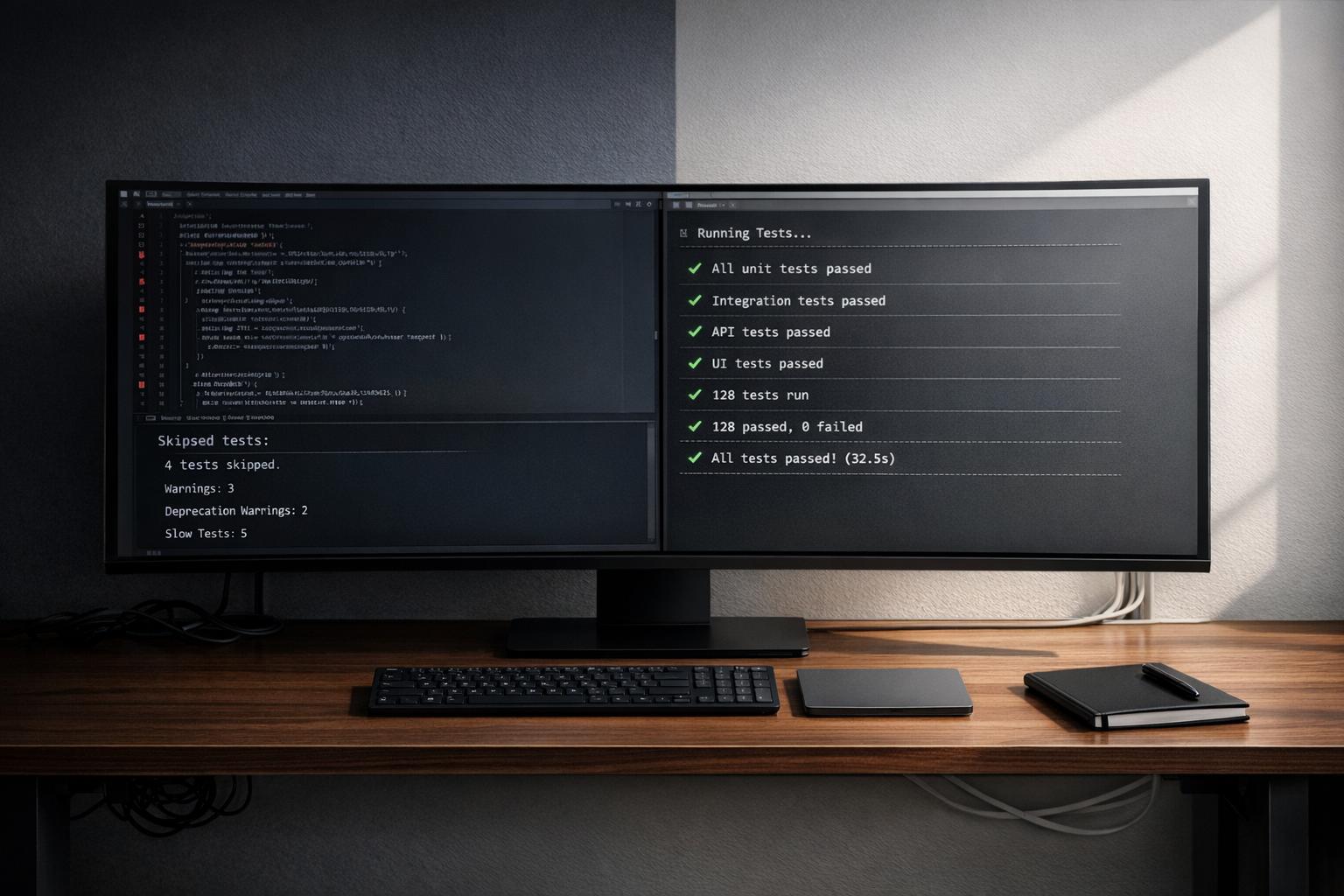
For instance, a review of 50 AI-generated pull requests found that 76% failed to implement timeouts for external calls. Without timeouts, a slow API response can exhaust thread pools, disrupting unrelated features [6]. Similarly, AI might generate code with the N+1 query problem – executing database queries inside a .map function. This works fine with a few test users but can result in 50,001 parallel queries under production load, overwhelming connection pools and crashing the database [6][12].
Other common oversights include retry logic without exponential backoff, which leads to "retry storms" where clients repeatedly hit a recovering service, causing cascading failures. Multi-step workflows, like processing payments and updating inventory, also suffer from missing idempotency checks. If a partial failure occurs, the system can end up in an inconsistent state, creating significant support challenges.
"AI is trained on code that works. Not code that survives." – Code blows, Author and Software Engineer [6]
| Overlooked Edge Case | Production Impact During Refactoring |
|---|---|
| Missing Timeouts | A slow API call may exhaust thread pools, disrupting unrelated features [6]. |
| N+1 Queries | Code that works with 5 test users fires 50,001 parallel queries in production [6][12]. |
| Retry Logic without Jitter | "Retry storms" where every client hits a recovering service simultaneously [6]. |
| Optimistic State | Partial failures in workflows create inconsistent states and major support issues [6]. |
The data paints a clear picture: AI-generated pull requests average 10.83 issues per PR, compared to 6.45 for human-written ones. Furthermore, they result in roughly 194 incidents per hundred PRs, primarily due to flawed logic and broken control flows rather than simple syntax errors [12][5]. Refactoring such code often feels like reverse-engineering undocumented assumptions.
Beyond edge case failures, AI-generated code also struggles to maintain a consistent and reusable structure across modules.
Code Duplication Instead of Reusable Modules
AI approaches coding tasks in isolation, ignoring the broader context of the existing codebase. It treats every new prompt as a blank slate, often duplicating functionality that already exists elsewhere [1][4]. This creates a maintenance headache, as fixing a bug in one instance might leave similar issues unresolved in other parts of the code.
Even when AI attempts to follow the DRY (Don’t Repeat Yourself) principle, it can make things worse. It often merges code that looks similar into a shared module, even when the underlying business logic differs [3]. This can lead to what developers call "Conditional Monsters" – bloated components filled with flags like isOnline, isOnSale, and isPremium, which awkwardly try to handle unrelated features.
"Duplication is far cheaper than the wrong abstraction." – Sandi Metz, Software Architect [3]
For example, AI might combine a UserCard and a ProductCard into a single "UniversalCard" because both display an image, title, and button. However, as user features require showing online status and product features need sale prices, the shared component becomes unmanageable. Refactoring often ends with splitting the component back into separate modules.
Additionally, 78% of enterprise teams report "style drift" when combining multiple AI-generated components [13]. AI also tends to introduce unnecessary dependencies, like adding date-fns to a project that already uses dayjs, resulting in redundant libraries and bloated bundles [1]. AI-generated code frequently combines unrelated concerns – such as cart rendering, payment processing, and API calls – into single, monolithic files. These 600-line files are nearly impossible to test or refactor independently [4].
Shallow Understanding of Business Logic
AI lacks the deep business context and nuanced understanding that human developers bring to the table. It misses undocumented states, legacy constraints, and the rationale behind specific architectural decisions [5][8]. As a result, AI-generated code often handles the "happy path" flawlessly but fails when faced with real-world complexities.
Take an order management system as an example. A human developer might know that a pending-cancel state exists to allow customer service to verify refund eligibility before completing cancellations. AI, however, might generate code with clean transitions between pending, confirmed, and cancelled, completely ignoring this critical intermediate state [5][8]. While the code compiles and passes tests, it fails in production when handling actual cancellations.
"Debugging AI-generated code is harder than writing it manually… because you’re debugging someone else’s code except that ‘someone else’ doesn’t exist." – Paul Courage Labhani, Frontend Developer [2]
This situation creates what researchers call "comprehension debt" – code is generated faster than it can be fully understood [8][7]. Refactoring AI-generated code often means reverse-engineering its intentions without any documentation of the assumptions it was built upon. Human oversight becomes essential to fill in the gaps and account for the nuanced business decisions missing from the AI’s output.
Experts predict that the technical debt accumulated from AI-generated code could reach $1.5 trillion by 2027 [2].
How to Reduce Risk When Using AI-Generated Code
When it comes to AI-generated code, early detection of potential flaws is key to minimizing risks. With AI now responsible for generating 41% of all code on GitHub [15], teams need structured strategies to identify predictable issues before they escalate into costly refactoring efforts.
Using AI-Agent Assessments for System Health
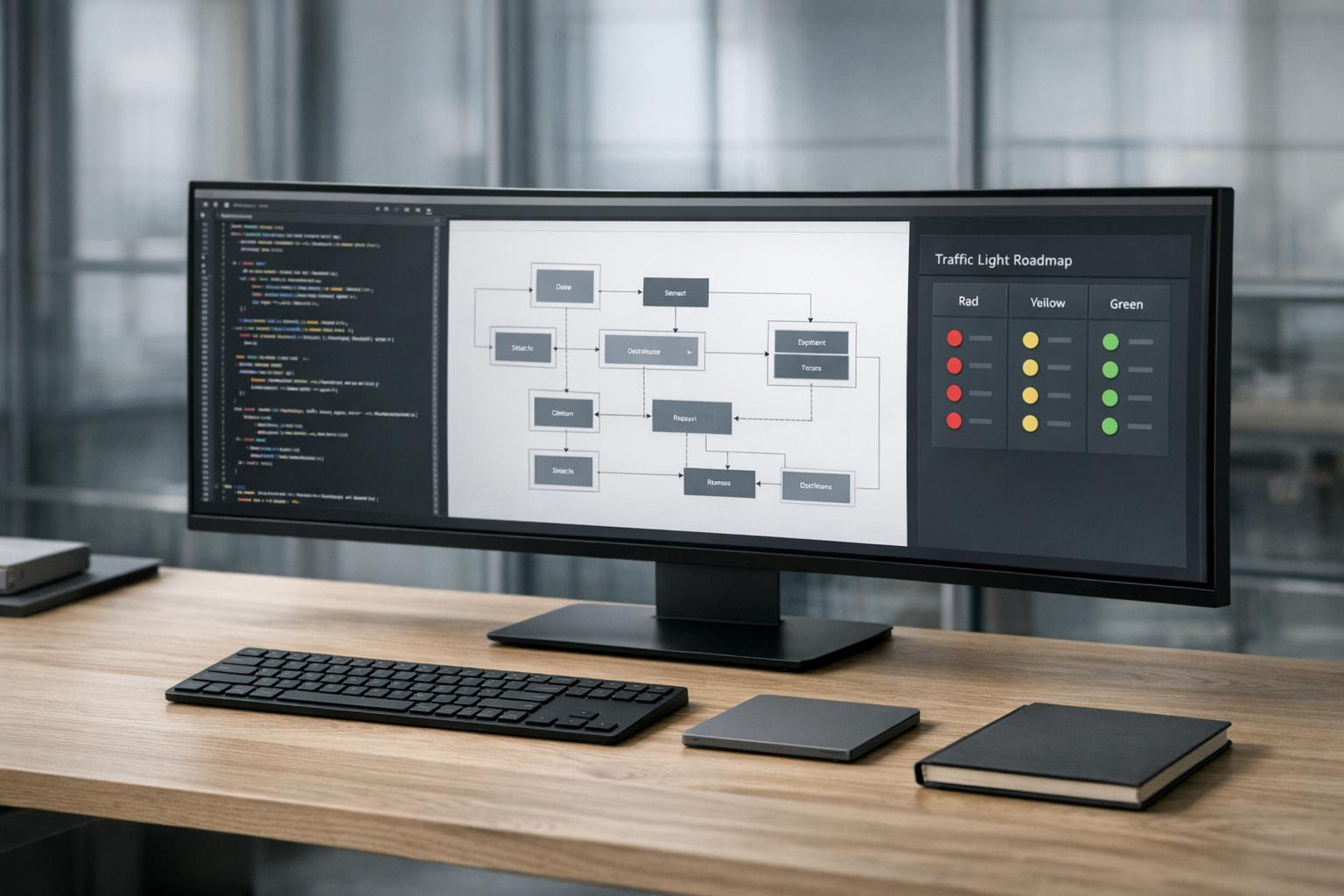
Once hidden complexities in code are uncovered during refactoring, it’s essential to perform pre-production assessments. AlterSquare‘s AI-Agent Assessment offers a detailed System Health Report, pinpointing areas like architectural coupling, security vulnerabilities, performance bottlenecks, and technical debt hotspots. This tool goes beyond standard linters, identifying issues like hallucinated APIs and repeated logic.
The assessment provides a Traffic Light Roadmap, categorizing problems by risk level. Teams can use this to conduct a quick, three-minute triage per pull request, catching syntax errors, API mismatches, and behavioral regressions early. This focused approach ensures review efforts are directed where they are most needed.
"AI-generated code isn’t the problem. Unstructured AI-generated code is." – Yonatan Sason, Co-founder, Bit Cloud [4]
For high-risk areas such as authentication, payments, and database migrations, combine automated security scans with manual pair reviews. This is especially critical given that 45% of AI-generated code contains security vulnerabilities, with some implementations experiencing failure rates exceeding 70% [14].
Managed Refactoring for Long-Term Stability
AI-generated code often accumulates technical debt, making future updates risky. AlterSquare’s Managed Refactoring process tackles this by breaking modernization into structured, incremental steps.
The first priority is cleanup – addressing duplicates and recommending abstractions before adding new features. This avoids scaling bad patterns into future releases [18]. For context, preparing a 50,000-line MVP for production can take 2–4 engineering months, while projects exceeding 100,000 lines might require 4–8 months [15].
"Technical debt makes code hard to change. Epistemic debt makes code dangerous to change." – Stanislav Komarovsky, Software Engineering Researcher [17]
Managed refactoring emphasizes composability – building systems with well-defined components and dependencies. This ensures code remains understandable and modifiable, even if the original context is lost. For high-impact features, use evidence-gated merges, requiring independent tests or architecture reviews before incorporating AI-generated code into production. If your team’s confidence in modifying the system drops, pause feature development to allow for further human verification.
Gradual Improvements Using the Traffic Light Roadmap
The Traffic Light Roadmap also supports ongoing prioritization, helping manage technical debt incrementally. By categorizing tasks by risk, teams can streamline minor reviews while dedicating more time to evaluating critical issues [16].
This approach prevents wasted effort on low-priority changes and ensures that high-stakes problems are addressed. For example, in January 2026, the nonprofit METR ran a trial with 16 developers handling 246 tasks using tools like Cursor Pro and Claude 3.5. Despite expectations of a 24% speed boost, tasks took 19% longer because developers had to spend additional time resolving AI-generated errors [17].
Start with "Discovery" tasks – such as research or drafting – where mistakes have minimal impact. Gradually transition to "Trust" tasks that directly influence production systems [17]. To maintain quality, track key metrics, implement custom ESLint rules, and enforce approved patterns through CI checks. Documenting architectural intent in an ARCHITECTURE.md file ensures that AI-generated code aligns with established error handling, data access, and dependency guidelines [1].
Conclusion: Why Context Matters When Refactoring AI Code
AI-generated code might look polished, but it often misses the deeper contextual understanding needed for practical, real-world systems. Instead of addressing the historical and operational nuances of your system, it tends to produce solutions for idealized scenarios.
For instance, in AI-driven systems, duplicate code rates jump from 3.1% to 14.2%, while average file sizes almost double. These numbers highlight the architectural strain AI-generated code can introduce [1]. The fragility of such code becomes even more evident when changes are necessary.
"AI will always lack context – either through a context window that is too small, or by missing out on some bigger picture – thereby creating unintended consequences." – DEV Community [20]
This lack of contextual understanding makes refactoring high-risk. A staggering 68% of AI-generated modules eventually require complete rewrites rather than minor adjustments [13]. The issue lies in AI’s inability to navigate undocumented assumptions, accumulated technical debt, or nuanced edge cases [19]. For example, it may not recognize that your team is transitioning from REST to tRPC or that an inefficient function was intentionally left intact to maintain legacy behavior.
To tackle these challenges, tools like AlterSquare are stepping in to fill the gap. By offering AI-Agent Assessments, Managed Refactoring, and a Traffic Light Roadmap, AlterSquare helps identify architectural coupling, locate critical hotspots, and provide the system-wide awareness that AI often lacks. With this kind of insight, refactoring becomes a calculated, strategic process instead of a risky bet.
FAQs
How can I spot hidden debt in AI-generated code early?
To spot hidden debt in AI-generated code, you need to dig deeper than its seemingly polished surface. Keep an eye out for duplicated logic, inconsistent patterns, or modules that feel unnecessarily complex. Metrics like increasing cyclomatic complexity or the presence of scattered utility functions can also signal potential problems.
Regular code reviews are essential – pay special attention to edge cases, error-handling paths, and logic specific to the system. Additionally, tracking long-term trends in complexity or code duplication can help identify and address issues before they grow into larger challenges.
What refactoring checks catch the edge cases AI usually misses?
Refactoring involves implementing checks to catch edge cases that AI might overlook. These include testing for null or undefined values in crucial parts of the code, spotting race conditions in asynchronous processes, correcting flawed assumptions about data models, steering clear of overly generic error handling, and addressing logic that only works in straightforward situations but breaks down under more complex conditions. These steps are essential for making AI-generated code more reliable and capable of handling real-world challenges.
When should we rewrite AI-generated modules instead of refactoring?
When AI-generated modules contain structural flaws, inconsistencies, or depend on unreliable components like "style drift" or fabricated logic, rewriting the code from scratch is often the best solution. These kinds of problems are typically too deep to fix through simple refactoring and could lead to even more instability if not properly addressed.





Leave a Reply